[ICML 2018] Day 3 - Energy, GANs, Rankings, Curriculum Learning, and our paper
[ICML 2018] Day 3 - Energy, GANs, Rankings, Curriculum Learning, and our paper
Day 3 of ICML 2018 started by a plenary talk by Max Welling on “Intelligence per Kilowatthour”. He talked about the interconnection between physics and AI (cf. energy, entropy, information, bits, minimum description length principle) both from the modelling side but also from the energy cost side. Current models (e.g. deep learning networks) are very greedy in energy. From physics energy (modelling) ideas stem a bayesian interpration of deep learning that can yield to more (physical) energy efficient models. Things finally come full circle. There a youtube video of one of his other talks on the subject which has a non-trivial intersection with the one given at ICML.
I went to the following sessions and particularly liked these papers:
- Generative Models (session 1)
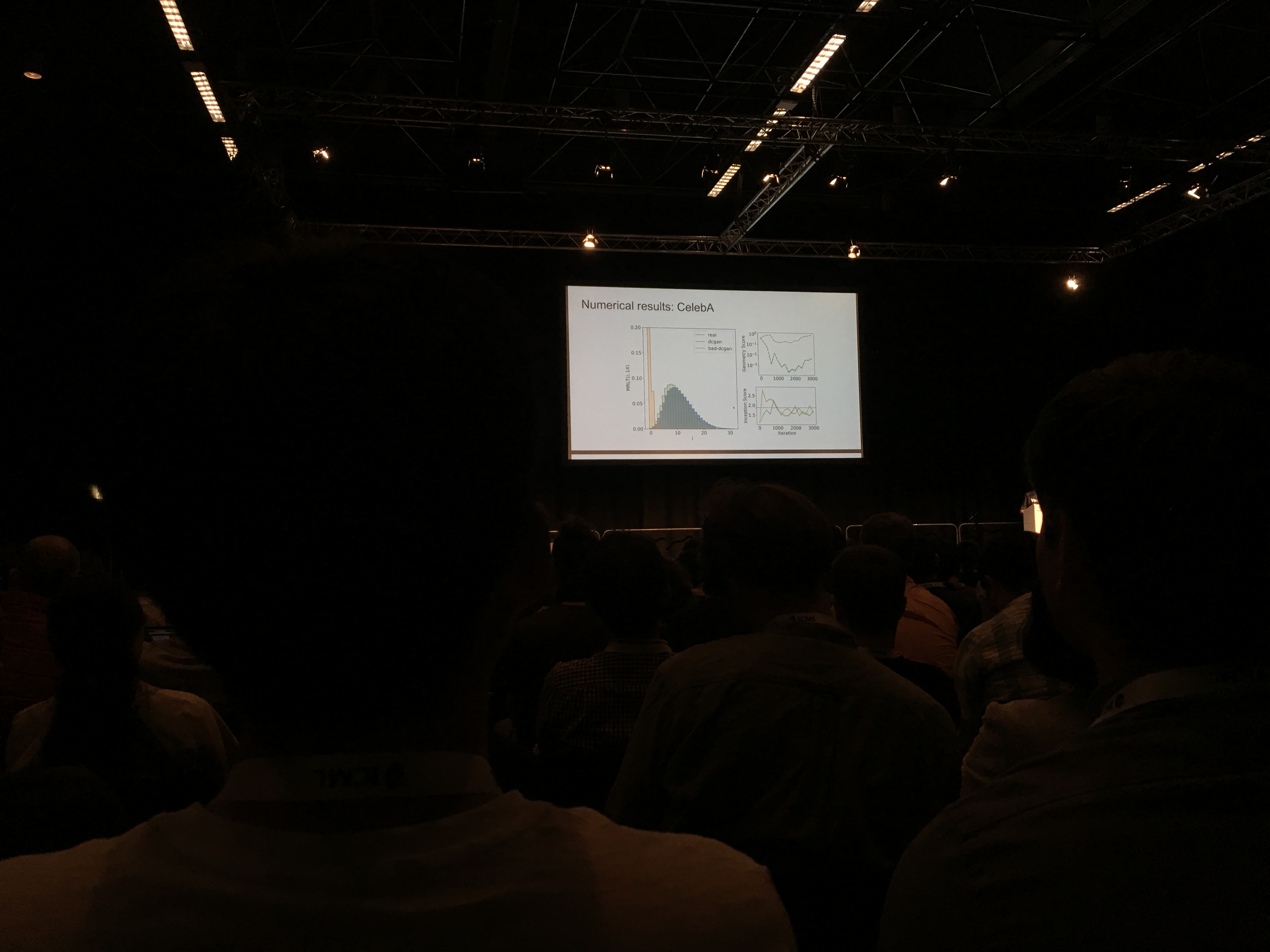
- Geometry Score: A Method For Comparing Generative Adversarial Networks Authors construct a novel measure of performance of a GAN (generative adversarial network) by comparing geometrical properties of the underlying data manifold and the generated one, which provides both qualitative and quantitative means for evaluation. Concretely, to study the data manifold, authors use Topological Data Analysis, i.e. a set of formalism and techniques to do topology on discrete point clouds (cf. this paper by Gunnar Carlsson for an in-depth introduction of TDA, and GUDHI (Geometry Understanding in Higher Dimensions) for a software library). (GitHub code)

- Ranking and Preference Learning (session 2A)
-
Accelerated Spectral Ranking The problem: Given pairwise or multiway comparisons among n items, the goal is to learn a score for each item. These scores can further be used to produce a ranking over these items. For example, in recommendation systems, the goal might be to learn a ranking over items by observing the choices that users make when presented with different subsets of these items. In the case of multiway comparisons, there is an algorithm called the Luce spectral ranking (LSR) which tackles the problem by constructing a random walk (equivalently a Markov chain) over the comparison graph on n items, where there is an edge between two items if they are compared in a pairwise or multiway comparison. This random walk is constructed such that its stationary distribution corresponds to the weights of the MNL/BTL model. Authors propose a faster algorithm to do that.
-
All the other papers of this session seemed quite interesting to me, but I am not familiar enough with the literature yet to comment. I will probably play with these approaches in a near future. There is a GitHub repo for SQL-Rank: A Listwise Approach to Collaborative Ranking.




-
- Supervised Learning (session 2B)
-
This Supervised Learning session contained presentations on problems very relevant to the practitioners: Learning on noisy labels; Improving the empirical convergence rate of the model. The latter can be done by using curriculum learning, i.e. presenting the easy examples to learn from first, and then increasing in difficulty. All the papers of this session seem to be impactful at a rather short horizon for the industry (Uber and Google AI heads among their authors, Raquel Urtasun and Fei-Fei Li respectively).
-
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels

-
Learning to Reweight Examples for Robust Deep Learning (Unofficial GitHub code)
-
Dimensionality-Driven Learning with Noisy Labels (GitHub code)

-
-
Deep Learning (Neural Network Architectures) (session 3)
-
Extracting Automata from Recurrent Neural Networks Using Queries and Counterexamples seems a very interesting paper for those like me who have been trained both in theoretical computer science and deep learning. Didn’t read through thoroughly yet though.
-
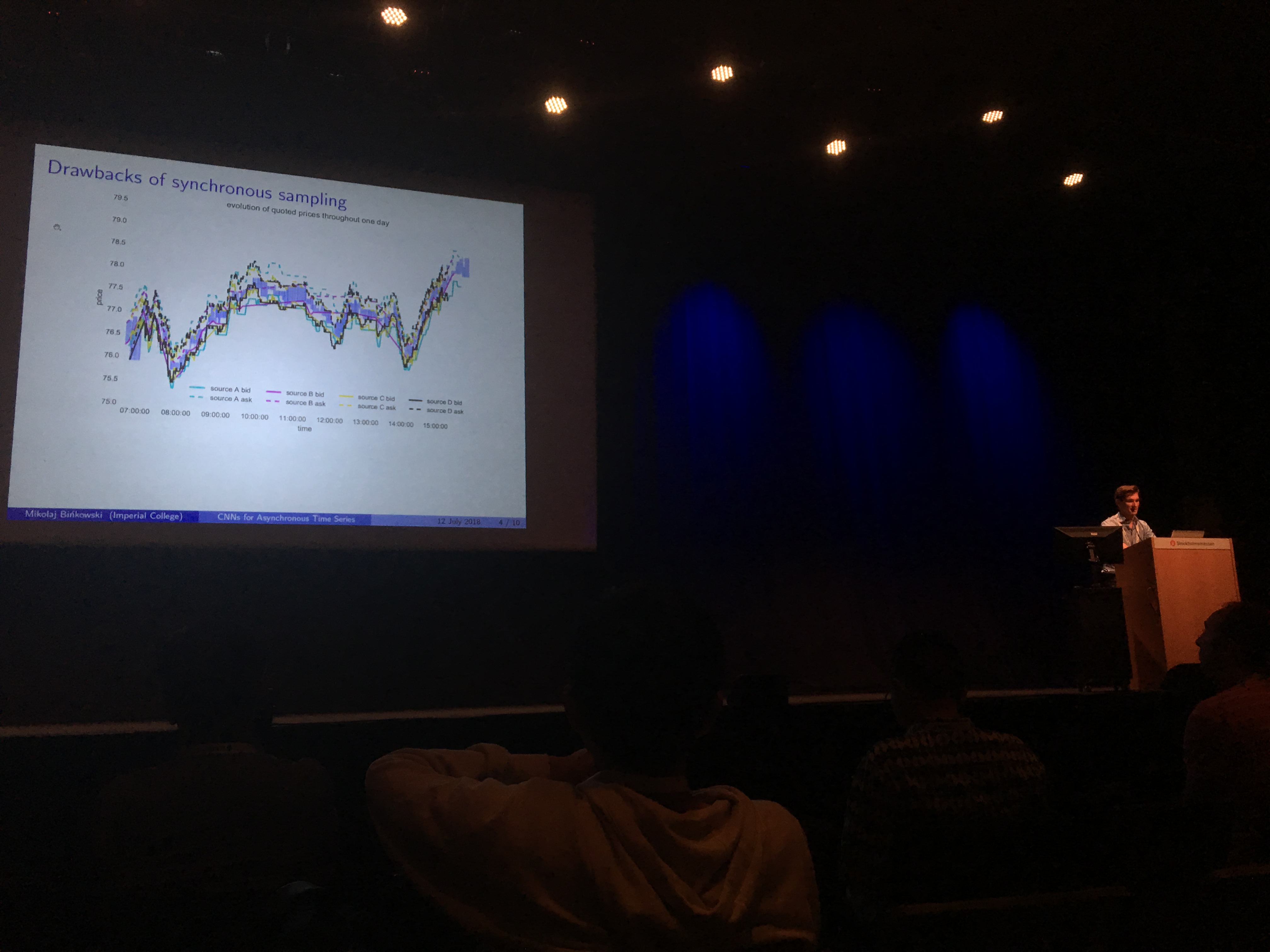
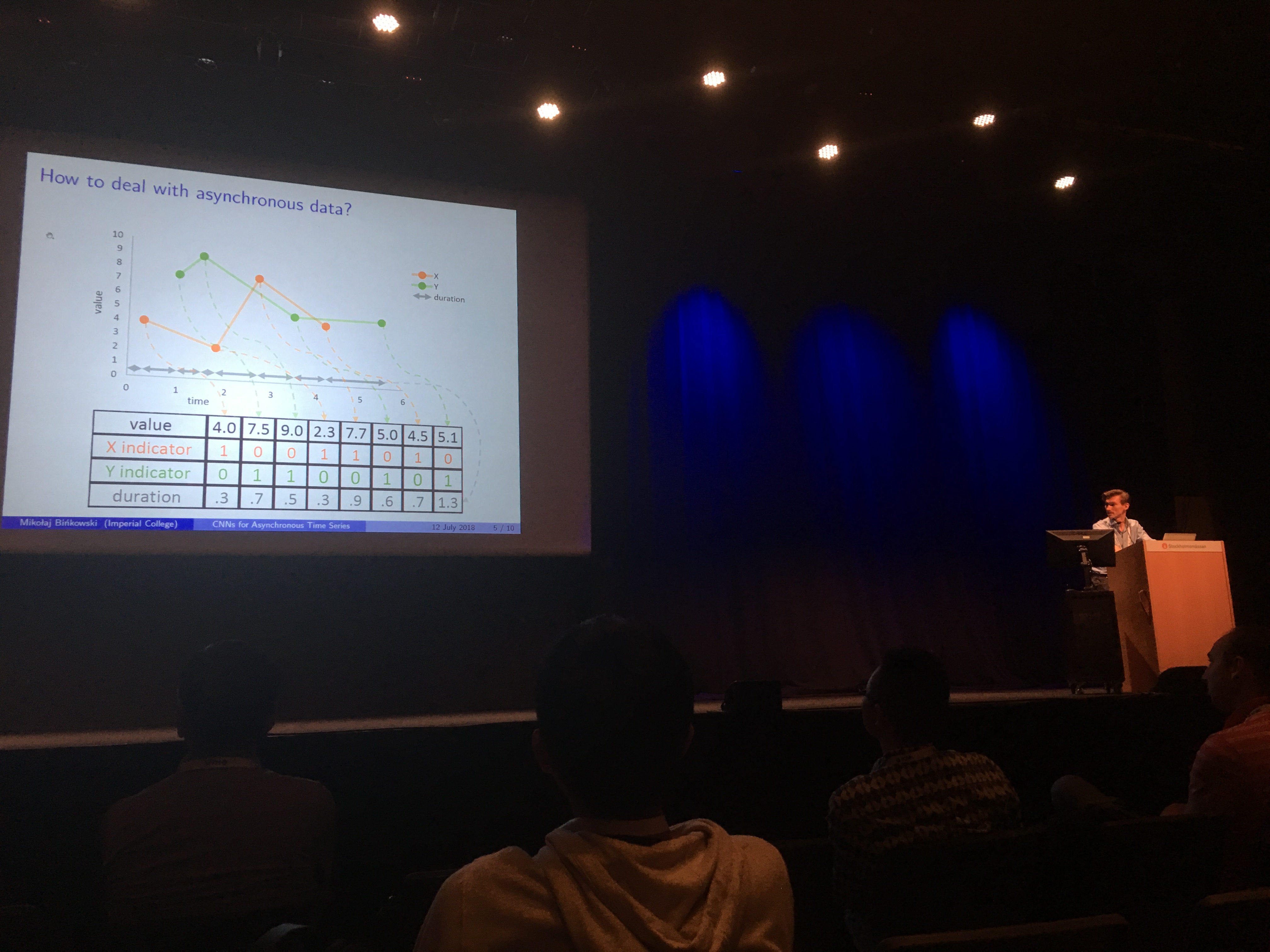
Autoregressive Convolutional Neural Networks for Asynchronous Time Series (GitHub code)
Our paper. Basically, an autoregressive model whose weights are non-linear and which can deal with asynchronous multivariate time series. For an example of applications, think of dealers contributing quotes in an OTC market: These quotes arrives at random times, and depending on the dealer more or less frequently, with some specific bias and variance, with potentially some lags in the market moves with respect to other dealers. The model aims to capture these relations, and the weights of the significance network allow some interpretation and visualization of the (lead-lag) relationships between these dealers. We may generalize this work to other econometric models. This work was done when Mikolaj and I were working for Hellebore Capital.
-

Aside the conference, JP Morgan presented at its booth its Deep Hedging approach.