On the difficulty of reading numbers in different languages
On the difficulty of reading numbers in different languages
This blog post illustrates how difficult it is for a simple seq2seq model to learn how to translate numbers from different languages (e.g. French, English, Chinese, Malay) to their digits (base 10) representation. It is based on the very good deep learning tutorials by Olivier Grisel and Charles Ollion. Note that this is a very simple seq2seq model, cf. fairseq or sockeye for more sophisticated ones.
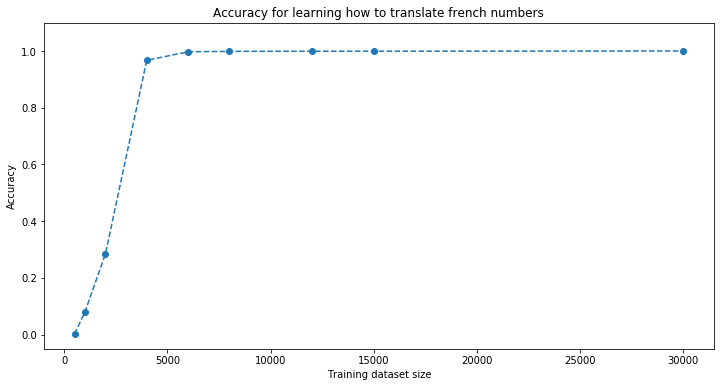
The experiment: We illustrate the convergence of the model to perfect prediction on the test set as a function of the training set size. Faster increasing accuracy indicates easier learning task, i.e. the model requires less training examples. The training set consists in randomly chosen numbers between 1 and 999,999. The model is fed with the language representation in input and has to output its digit (base 10) representation.
TL;DR
-
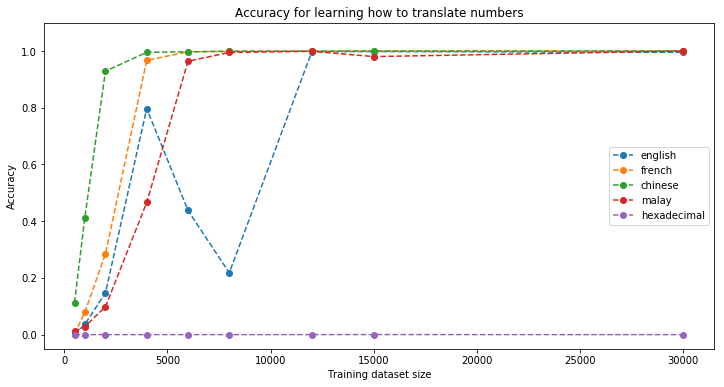
Chinese is the easiest to learn, then French (despite its seemingly many particular cases such as ‘vingt’ vs. ‘vingts’ and ‘cent’ vs. ‘cents’), closely followed by Malay. English is not that easy (maybe because of the ‘-‘s that have to be forgotten).
-
By looking at French examples, we might think that the model acquire some basic reasoning on arithmetic. Consider:
- “quatre vingts”, literally meaning “four twenty”, stands for “80” (and not 420), i.e. it can be interpreted as the multiplication of four by twenty; Or even more complicated:
- “quatre vingt onze mille”, literally meaning “four twenty eleven thousand”, which stands for “91000” (and not 420111000), i.e. it has to be interpreted as (4 * 20 + 11) * 1000.
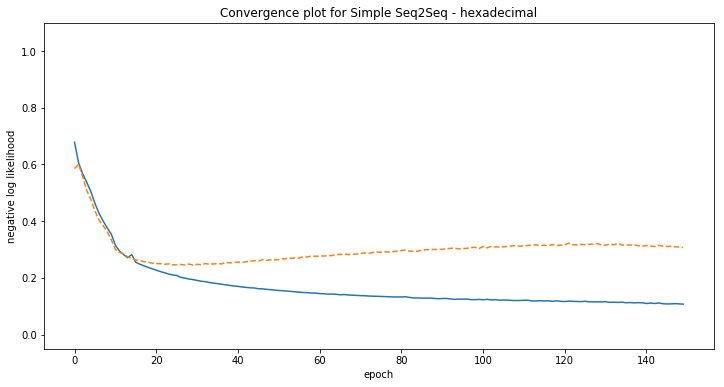
To check whether the model is able to acquire some basic arithmetic skills, we have added the task of translating from hexadecimal to base 10 digits. Considering its poor results, it is unlikely that the model learns any arithmetic at all for performing its translation task. However, this task is more difficult (implicit base 16, and exponentiation based on the digit position). More on that in later posts…
from collections import OrderedDict
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Embedding, Dropout, GRU, Dense
from keras.callbacks import ModelCheckpoint
from keras.models import load_model
from hexadecimal_numbers import to_hexadecimal_phrase
import matplotlib.pyplot as plt
%matplotlib inline
Using TensorFlow backend.
languages = [
'english',
'french',
'chinese',
'malay',
'hexadecimal',
]
examples = {}
examples['english'] = [
"one",
"two",
"three",
"eleven",
"fifteen",
"one hundred thirty-two",
"one hundred twelve",
"seven thousand eight hundred fifty-nine",
"twenty-one",
"twenty-four",
"eighty",
"ninety-one thousand",
"ninety-one thousand two hundred two",
]
examples['french'] = [
"un",
"deux",
"trois",
"onze",
"quinze",
"cent trente deux",
"cent mille douze",
"sept mille huit cent cinquante neuf",
"vingt et un",
"vingt quatre",
"quatre vingts",
"quatre vingt onze mille",
"quatre vingt onze mille deux cent deux",
]
examples['chinese'] = [
"一",
"二",
"三",
"十一",
"十五",
"一百三十二",
"十万十二",
"七千八百五十九",
"二十一",
"二十四",
"八十",
"九万一千",
"九万一千两百零二",
]
examples['malay'] = [
"satu",
"dua",
"tiga",
"sebelas",
"lima belas",
"seratus tiga puluh dua",
"seratus ribu dua belas",
"tujuh ribu lapan ratus lima puluh sembilan",
"dua puluh satu",
"dua puluh empat",
"lapan puluh",
"sembilan puluh satu ribu",
"sembilan puluh satu ribu dua ratus dua",
]
examples['hexadecimal'] = [
to_hexadecimal_phrase(1),
to_hexadecimal_phrase(2),
to_hexadecimal_phrase(3),
to_hexadecimal_phrase(11),
to_hexadecimal_phrase(15),
to_hexadecimal_phrase(132),
to_hexadecimal_phrase(100012),
to_hexadecimal_phrase(7859),
to_hexadecimal_phrase(21),
to_hexadecimal_phrase(24),
to_hexadecimal_phrase(80),
to_hexadecimal_phrase(91000),
to_hexadecimal_phrase(91202),
]
PAD, GO, EOS, UNK = START_VOCAB = ['_PAD', '_GO', '_EOS', '_UNK']
def build_vocabulary(tokenized_sequences):
rev_vocabulary = START_VOCAB[:]
unique_tokens = set()
for tokens in tokenized_sequences:
unique_tokens.update(tokens)
rev_vocabulary += sorted(unique_tokens)
vocabulary = {}
for i, token in enumerate(rev_vocabulary):
vocabulary[token] = i
return vocabulary, rev_vocabulary
def make_input_output(source_tokens, target_tokens, reverse_source=True):
if reverse_source:
source_tokens = list(reversed(source_tokens))
input_tokens = source_tokens + [GO] + target_tokens
output_tokens = target_tokens + [EOS]
return input_tokens, output_tokens
def vectorize_corpus(source_sequences, target_sequences, shared_vocab,
word_level_source=True, word_level_target=True,
max_length=20):
assert len(source_sequences) == len(target_sequences)
n_sequences = len(source_sequences)
source_ids = np.empty(shape=(n_sequences, max_length), dtype=np.int32)
source_ids.fill(shared_vocab[PAD])
target_ids = np.empty(shape=(n_sequences, max_length), dtype=np.int32)
target_ids.fill(shared_vocab[PAD])
numbered_pairs = zip(range(n_sequences), source_sequences, target_sequences)
for i, source_seq, target_seq in numbered_pairs:
source_tokens = tokenize(source_seq, word_level=word_level_source)
target_tokens = tokenize(target_seq, word_level=word_level_target)
in_tokens, out_tokens = make_input_output(source_tokens, target_tokens)
in_token_ids = [shared_vocab.get(t, UNK) for t in in_tokens]
source_ids[i, -len(in_token_ids):] = in_token_ids
out_token_ids = [shared_vocab.get(t, UNK) for t in out_tokens]
target_ids[i, -len(out_token_ids):] = out_token_ids
return source_ids, target_ids
def greedy_translate(model, source_sequence, shared_vocab, rev_shared_vocab,
word_level_source=True, word_level_target=True):
"""Greedy decoder recursively predicting one token at a time"""
# Initialize the list of input token ids with the source sequence
source_tokens = tokenize(source_sequence, word_level=word_level_source)
input_ids = [shared_vocab.get(t, UNK) for t in reversed(source_tokens)]
input_ids += [shared_vocab[GO]]
# Prepare a fixed size numpy array that matches the expected input
# shape for the model
input_array = np.empty(shape=(1, model.input_shape[1]),
dtype=np.int32)
decoded_tokens = []
while len(input_ids) <= max_length:
# Vectorize a the list of input tokens as
# and use zeros padding.
input_array.fill(shared_vocab[PAD])
input_array[0, -len(input_ids):] = input_ids
# Predict the next output: greedy decoding with argmax
next_token_id = model.predict(input_array)[0, -1].argmax()
# Stop decoding if the network predicts end of sentence:
if next_token_id == shared_vocab[EOS]:
break
# Otherwise use the reverse vocabulary to map the prediction
# back to the string space
decoded_tokens.append(rev_shared_vocab[next_token_id])
# Append prediction to input sequence to predict the next
input_ids.append(next_token_id)
separator = " " if word_level_target else ""
return separator.join(decoded_tokens)
def phrase_accuracy(model, num_sequences, lg_sequences, n_samples=None,
decoder_func=greedy_translate):
correct = []
n_samples = len(num_sequences) if n_samples is None else n_samples
for i, num_seq, lg_seq in zip(range(n_samples), num_sequences, lg_sequences):
predicted_seq = decoder_func(model, lg_seq,
shared_vocab, rev_shared_vocab,
word_level_target=False)
correct.append(num_seq == predicted_seq)
return np.mean(correct)
accuracy = {}
for language in languages:
if language == 'english':
from english_numbers import generate_translations, tokenize
elif language == 'french':
from french_numbers import generate_translations, tokenize
elif language == 'chinese':
from chinese_numbers import generate_translations, tokenize
elif language == 'malay':
from malay_numbers import generate_translations, tokenize
elif language == 'hexadecimal':
from hexadecimal_numbers import generate_translations, tokenize
train = pd.read_hdf('./datasets/train/{}_numbers.h5'.format(language))
validation = pd.read_hdf('./datasets/validation/{}_numbers.h5'.format(language))
test = pd.read_hdf('./datasets/test/{}_numbers.h5'.format(language))
accuracy[language] = OrderedDict()
# loop here over the size of the training set
for train_size in [500, 1000, 2000, 4000, 6000, 8000, 12000, 15000, 30000]:
tokenized_lg_train = [tokenize(s, word_level=True) for s in train['language'][:train_size]]
tokenized_num_train = [tokenize(s, word_level=False) for s in train['digits'][:train_size]]
lg_vocab, rev_lg_vocab = build_vocabulary(tokenized_lg_train)
num_vocab, rev_num_vocab = build_vocabulary(tokenized_num_train)
all_tokenized_sequences = tokenized_lg_train + tokenized_num_train
shared_vocab, rev_shared_vocab = build_vocabulary(all_tokenized_sequences)
max_length = 20
X_train, Y_train = vectorize_corpus(train['language'][:train_size], train['digits'][:train_size],
shared_vocab, word_level_target=False,
max_length=max_length)
X_validation, Y_validation = vectorize_corpus(validation['language'], validation['digits'],
shared_vocab, word_level_target=False,
max_length=max_length)
X_test, Y_test = vectorize_corpus(test['language'], test['digits'],
shared_vocab, word_level_target=False,
max_length=max_length)
vocab_size = len(shared_vocab)
simple_seq2seq = Sequential()
simple_seq2seq.add(Embedding(vocab_size, 32, input_length=max_length))
simple_seq2seq.add(Dropout(0.2))
simple_seq2seq.add(GRU(256, return_sequences=True))
simple_seq2seq.add(Dense(vocab_size, activation='softmax'))
simple_seq2seq.compile(optimizer='adam',
loss='sparse_categorical_crossentropy')
best_model_fname = "{}_simple_seq2seq_checkpoint.h5".format(language)
best_model_cb = ModelCheckpoint(best_model_fname, monitor='val_loss',
save_best_only=True, verbose=0)
history = simple_seq2seq.fit(X_train, np.expand_dims(Y_train, -1),
validation_data=(X_validation,
np.expand_dims(Y_validation, -1)),
epochs=150, verbose=0, batch_size=32,
callbacks=[best_model_cb])
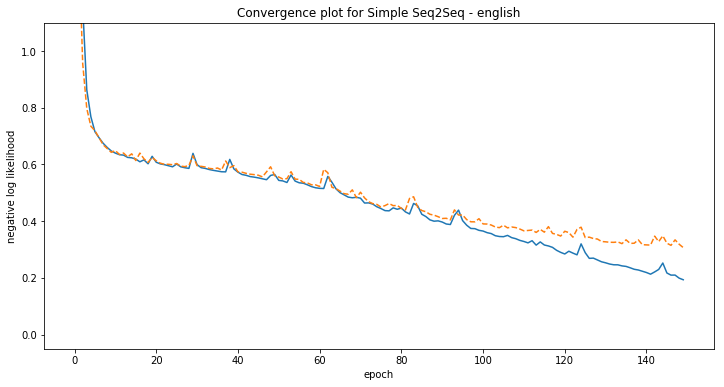
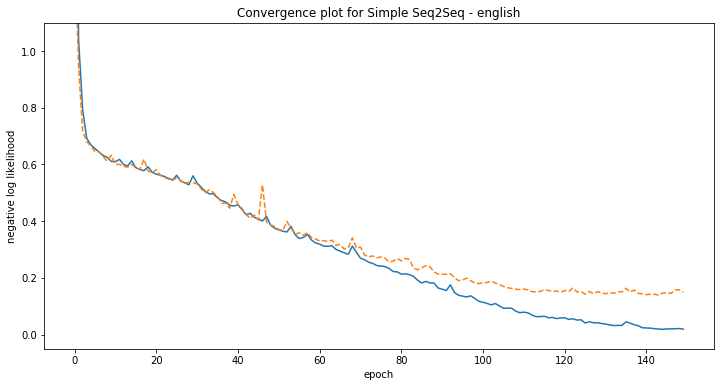
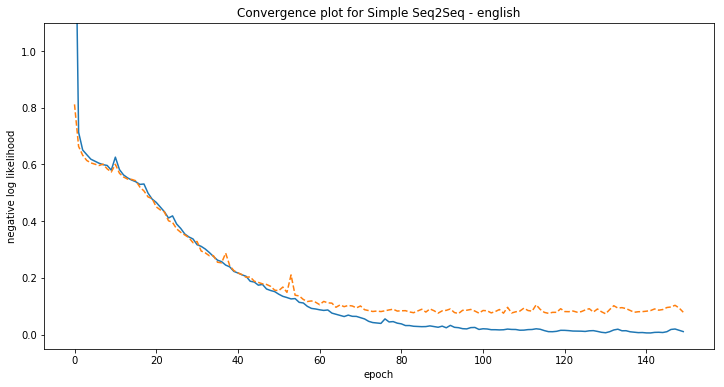
plt.figure(figsize=(12, 6))
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], '--', label='validation')
plt.ylabel('negative log likelihood')
plt.xlabel('epoch')
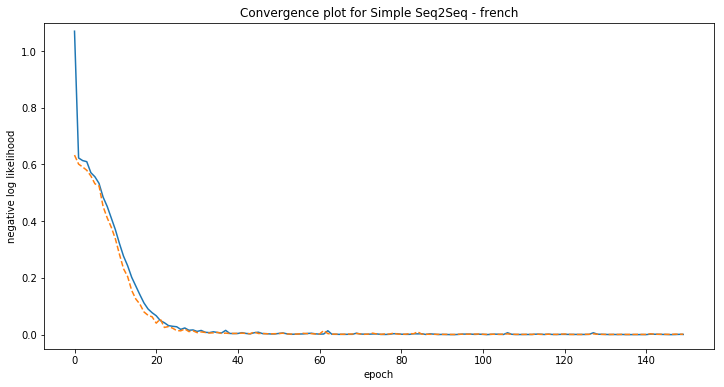
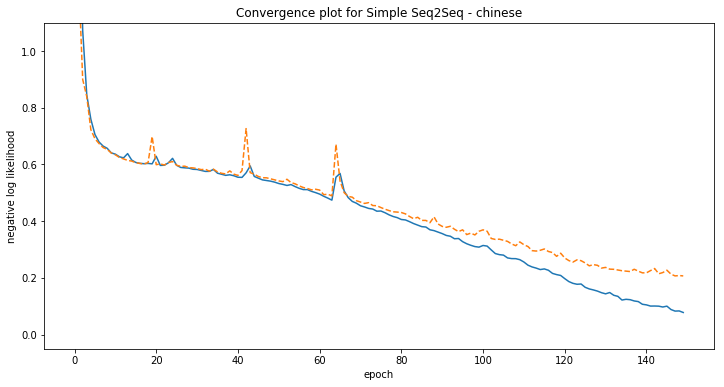
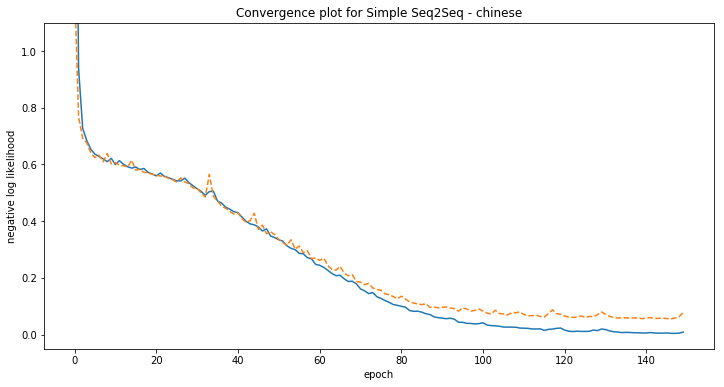
plt.title('Convergence plot for Simple Seq2Seq - {}'.format(language))
plt.ylim([-0.05, 1.1])
plt.show()
simple_seq2seq = load_model(best_model_fname)
print("Some examples of model predictions:")
print("-----------------------------------")
for phrase in examples[language]:
translation = greedy_translate(simple_seq2seq, phrase,
shared_vocab, rev_shared_vocab,
word_level_target=False)
print(phrase.ljust(50), translation)
prediction_accuracy = phrase_accuracy(simple_seq2seq, test['digits'], test['language'])
accuracy[language][train_size] = prediction_accuracy
print("\n[{}] Phrase-level test accuracy is %0.3f when training with dataset size = {}.\n\n\n"
.format(language, train_size) % prediction_accuracy)
# display the accuracy curve as function of the train size
plt.figure(figsize=(12, 6))
plt.plot(list(accuracy[language].keys()),
list(accuracy[language].values()),
'--o')
plt.ylabel('Accuracy')
plt.xlabel('Training dataset size')
plt.title('Accuracy for learning how to translate {} numbers'.format(language))
plt.ylim([-0.05, 1.1])
plt.show()
Some examples of model predictions:
-----------------------------------
one 15410
two 571
three 5710
eleven 11440
fifteen 4741
one hundred thirty-two 15
one hundred twelve 1174
seven thousand eight hundred fifty-nine
twenty-one 8101
twenty-four 54
eighty 871
ninety-one thousand 914
ninety-one thousand two hundred two 712
[english] Phrase-level test accuracy is 0.001 when training with dataset size = 500.
Some examples of model predictions:
-----------------------------------
one 18000
two 4000
three 390
eleven 11006
fifteen 13000
one hundred thirty-two 17
one hundred twelve 18012
seven thousand eight hundred fifty-nine 5859
twenty-one 2101
twenty-four 6
eighty 8900
ninety-one thousand 918
ninety-one thousand two hundred two 91220
[english] Phrase-level test accuracy is 0.036 when training with dataset size = 1000.
Some examples of model predictions:
-----------------------------------
one 18
two 2
three 4
eleven 11000
fifteen 85015
one hundred thirty-two 142
one hundred twelve 182
seven thousand eight hundred fifty-nine 7859
twenty-one 21
twenty-four 2
eighty 81
ninety-one thousand 91
ninety-one thousand two hundred two 9122
[english] Phrase-level test accuracy is 0.148 when training with dataset size = 2000.
Some examples of model predictions:
-----------------------------------
one 10
two 20
three 300
eleven 1101
fifteen 15005
one hundred thirty-two 132
one hundred twelve 112
seven thousand eight hundred fifty-nine 7859
twenty-one 214
twenty-four 24
eighty 80
ninety-one thousand 910
ninety-one thousand two hundred two 91202
[english] Phrase-level test accuracy is 0.797 when training with dataset size = 4000.
Some examples of model predictions:
-----------------------------------
one 180
two 20
three 30
eleven 1_PAD006
fifteen 1_PAD020
one hundred thirty-two 132
one hundred twelve 1212
seven thousand eight hundred fifty-nine 7959
twenty-one 210
twenty-four 24
eighty 80
ninety-one thousand 91000
ninety-one thousand two hundred two 91202
[english] Phrase-level test accuracy is 0.438 when training with dataset size = 6000.
Some examples of model predictions:
-----------------------------------
one 50
two 20
three 30
eleven 11
fifteen 15
one hundred thirty-two 932
one hundred twelve 121
seven thousand eight hundred fifty-nine 7859
twenty-one 29
twenty-four 2
eighty 80
ninety-one thousand 920
ninety-one thousand two hundred two 91002
[english] Phrase-level test accuracy is 0.218 when training with dataset size = 8000.

Some examples of model predictions:
-----------------------------------
one 1
two 2
three 3
eleven 11
fifteen 15
one hundred thirty-two 132
one hundred twelve 121
seven thousand eight hundred fifty-nine 7859
twenty-one 21
twenty-four 24
eighty 80
ninety-one thousand 91000
ninety-one thousand two hundred two 91202
[english] Phrase-level test accuracy is 0.997 when training with dataset size = 12000.

Some examples of model predictions:
-----------------------------------
one 1
two 2
three 3
eleven 11
fifteen 15
one hundred thirty-two 132
one hundred twelve 112
seven thousand eight hundred fifty-nine 7859
twenty-one 21
twenty-four 24
eighty 80
ninety-one thousand 91000
ninety-one thousand two hundred two 91202
[english] Phrase-level test accuracy is 0.998 when training with dataset size = 15000.

Some examples of model predictions:
-----------------------------------
one 1
two 2
three 3
eleven 11
fifteen 15
one hundred thirty-two 132
one hundred twelve 112
seven thousand eight hundred fifty-nine 7859
twenty-one 21
twenty-four 24
eighty 80
ninety-one thousand 91000
ninety-one thousand two hundred two 91202
[english] Phrase-level test accuracy is 0.995 when training with dataset size = 30000.
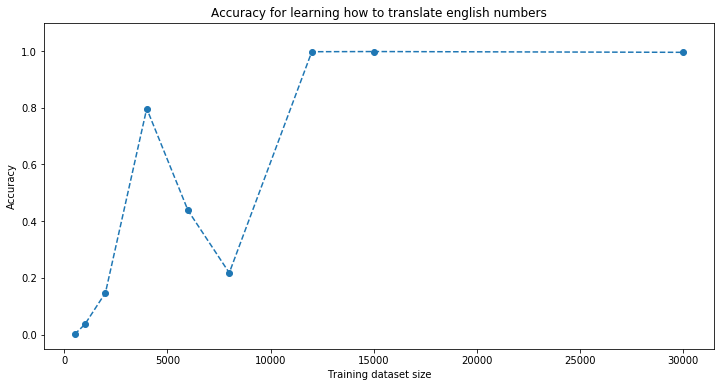
Some examples of model predictions:
-----------------------------------
un 1012
deux 200
trois 510
onze 1112
quinze 191
cent trente deux 15
cent mille douze 191
sept mille huit cent cinquante neuf 766
vingt et un 910
vingt quatre 21
quatre vingts 90
quatre vingt onze mille 9190
quatre vingt onze mille deux cent deux 912
[french] Phrase-level test accuracy is 0.002 when training with dataset size = 500.
Some examples of model predictions:
-----------------------------------
un 102
deux 2
trois 30
onze 102
quinze 10
cent trente deux 132
cent mille douze 132
sept mille huit cent cinquante neuf 7880
vingt et un 21
vingt quatre 2
quatre vingts
quatre vingt onze mille 90130
quatre vingt onze mille deux cent deux 93222
[french] Phrase-level test accuracy is 0.079 when training with dataset size = 1000.
Some examples of model predictions:
-----------------------------------
un 10
deux 2
trois 3
onze 11
quinze 15
cent trente deux 132
cent mille douze 15202
sept mille huit cent cinquante neuf 9859
vingt et un 21
vingt quatre 48
quatre vingts 8402
quatre vingt onze mille 91
quatre vingt onze mille deux cent deux 91202
[french] Phrase-level test accuracy is 0.285 when training with dataset size = 2000.
Some examples of model predictions:
-----------------------------------
un 1008
deux 200
trois 300
onze 110
quinze 15000
cent trente deux 132
cent mille douze 100012
sept mille huit cent cinquante neuf 7859
vingt et un 21
vingt quatre 24
quatre vingts 80
quatre vingt onze mille 91
quatre vingt onze mille deux cent deux 91202
[french] Phrase-level test accuracy is 0.967 when training with dataset size = 4000.
Some examples of model predictions:
-----------------------------------
un 71
deux 21
trois 31
onze 11
quinze 150
cent trente deux 132
cent mille douze 100012
sept mille huit cent cinquante neuf 7859
vingt et un 20081
vingt quatre 20
quatre vingts 80
quatre vingt onze mille 91000
quatre vingt onze mille deux cent deux 91202
[french] Phrase-level test accuracy is 0.997 when training with dataset size = 6000.

Some examples of model predictions:
-----------------------------------
un 10
deux 20
trois 31
onze 11
quinze 55005
cent trente deux 132
cent mille douze 100012
sept mille huit cent cinquante neuf 7859
vingt et un 25
vingt quatre 24
quatre vingts 80
quatre vingt onze mille 91
quatre vingt onze mille deux cent deux 91202
[french] Phrase-level test accuracy is 0.999 when training with dataset size = 8000.

Some examples of model predictions:
-----------------------------------
un 1
deux 2102
trois 3032
onze 10
quinze 15
cent trente deux 132
cent mille douze 100012
sept mille huit cent cinquante neuf 7859
vingt et un 22
vingt quatre 24
quatre vingts 80
quatre vingt onze mille 91000
quatre vingt onze mille deux cent deux 91202
[french] Phrase-level test accuracy is 0.999 when training with dataset size = 12000.

Some examples of model predictions:
-----------------------------------
un 1
deux 2
trois 3
onze 11
quinze 15
cent trente deux 132
cent mille douze 100012
sept mille huit cent cinquante neuf 7859
vingt et un 27
vingt quatre 24
quatre vingts 80
quatre vingt onze mille 91000
quatre vingt onze mille deux cent deux 91202
[french] Phrase-level test accuracy is 0.999 when training with dataset size = 15000.

Some examples of model predictions:
-----------------------------------
un 1
deux 2
trois 3
onze 11
quinze 15
cent trente deux 132
cent mille douze 100012
sept mille huit cent cinquante neuf 7859
vingt et un 21
vingt quatre 24
quatre vingts 80
quatre vingt onze mille 91000
quatre vingt onze mille deux cent deux 91202
[french] Phrase-level test accuracy is 1.000 when training with dataset size = 30000.
Some examples of model predictions:
-----------------------------------
一 110711
二 41071
三 41071
十一 110111
十五 10005
一百三十二 150
十万十二 100012
七千八百五十九 7824
二十一 41011
二十四 540040
八十 910710
九万一千 91010
九万一千两百零二 91202
[chinese] Phrase-level test accuracy is 0.113 when training with dataset size = 500.
Some examples of model predictions:
-----------------------------------
一 10020
二 200020
三 30020
十一 11001
十五 180
一百三十二 132
十万十二 12002
七千八百五十九 7859
二十一 20001
二十四 2400
八十 800020
九万一千 91010
九万一千两百零二 91202
[chinese] Phrase-level test accuracy is 0.413 when training with dataset size = 1000.
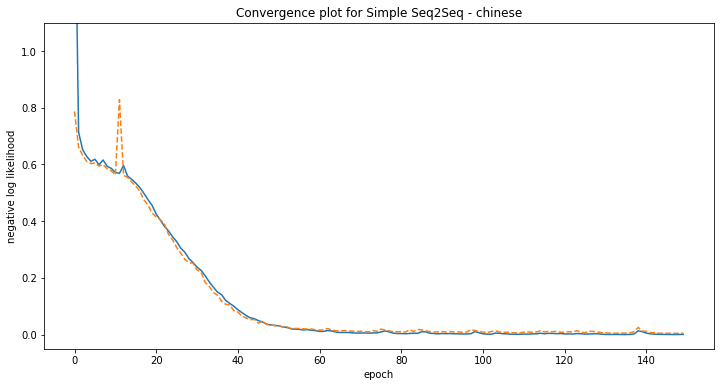
Some examples of model predictions:
-----------------------------------
一 10000
二 20000
三 30000
十一 100011
十五 100055
一百三十二 132
十万十二 100010
七千八百五十九 7859
二十一 250111
二十四 24
八十 80000
九万一千 91010
九万一千两百零二 91202
[chinese] Phrase-level test accuracy is 0.929 when training with dataset size = 2000.
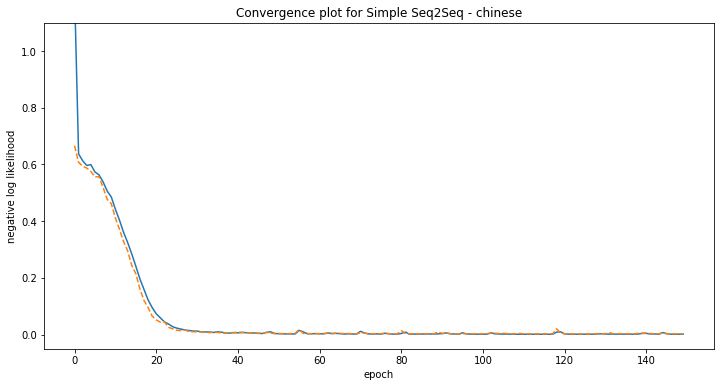
Some examples of model predictions:
-----------------------------------
一 10000
二 20060
三 30000
十一 1_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD
十五 _PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD
一百三十二 132
十万十二 100012
七千八百五十九 7859
二十一 200121
二十四 240_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD_PAD
八十 800100
九万一千 91000
九万一千两百零二 91202
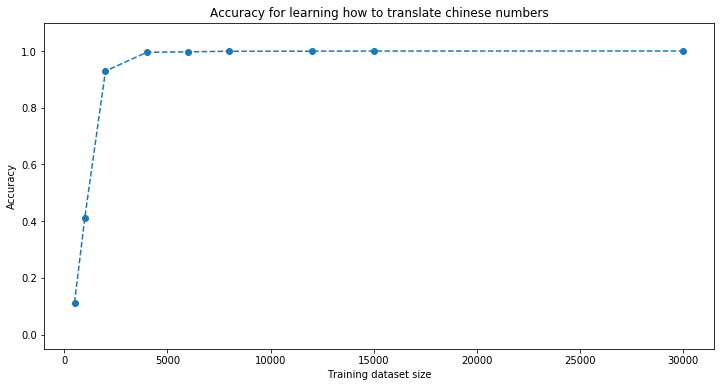
[chinese] Phrase-level test accuracy is 0.995 when training with dataset size = 4000.
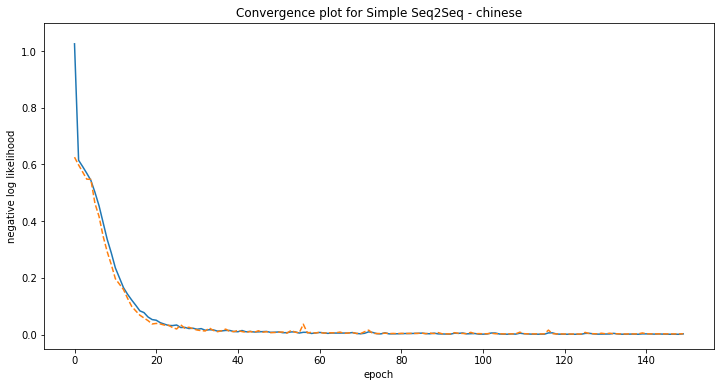
Some examples of model predictions:
-----------------------------------
一 10000
二 20000
三 30000
十一 110011
十五 100015
一百三十二 132
十万十二 100012
七千八百五十九 7859
二十一 20011
二十四 280044
八十 80010
九万一千 91000
九万一千两百零二 91202
[chinese] Phrase-level test accuracy is 0.997 when training with dataset size = 6000.

Some examples of model predictions:
-----------------------------------
一 10000
二 20000
三 30000
十一 17
十五 154005
一百三十二 132
十万十二 100012
七千八百五十九 7859
二十一 21
二十四 24
八十 80
九万一千 91000
九万一千两百零二 91202
[chinese] Phrase-level test accuracy is 0.999 when training with dataset size = 8000.
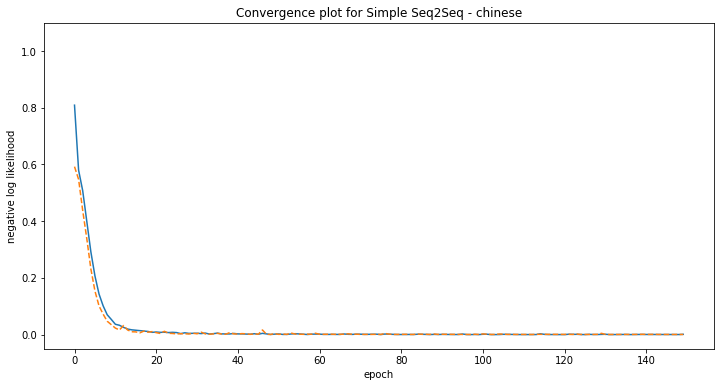
Some examples of model predictions:
-----------------------------------
一 1
二 20
三 300000
十一 11
十五 15
一百三十二 132
十万十二 100012
七千八百五十九 7859
二十一 21
二十四 24
八十 80
九万一千 91000
九万一千两百零二 91202
[chinese] Phrase-level test accuracy is 0.999 when training with dataset size = 12000.

Some examples of model predictions:
-----------------------------------
一 1
二 20
三 3
十一 11
十五 15
一百三十二 132
十万十二 100012
七千八百五十九 7859
二十一 21
二十四 24
八十 80
九万一千 91000
九万一千两百零二 91202
[chinese] Phrase-level test accuracy is 1.000 when training with dataset size = 15000.

Some examples of model predictions:
-----------------------------------
一 1
二 2
三 3
十一 11
十五 15
一百三十二 132
十万十二 100012
七千八百五十九 7859
二十一 21
二十四 24
八十 80
九万一千 91000
九万一千两百零二 91202
[chinese] Phrase-level test accuracy is 1.000 when training with dataset size = 30000.
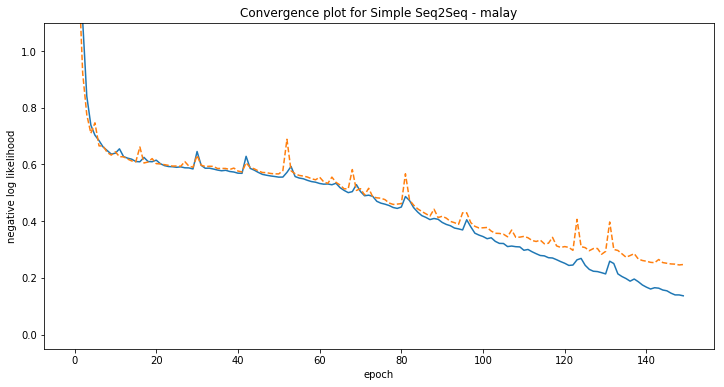
Some examples of model predictions:
-----------------------------------
satu 1174
dua 5
tiga 6
sebelas 1144
lima belas 1514
seratus tiga puluh dua 159
seratus ribu dua belas 1052
tujuh ribu lapan ratus lima puluh sembilan 5653
dua puluh satu 214
dua puluh empat 57
lapan puluh 87
sembilan puluh satu ribu 9171
sembilan puluh satu ribu dua ratus dua 9125
[malay] Phrase-level test accuracy is 0.012 when training with dataset size = 500.
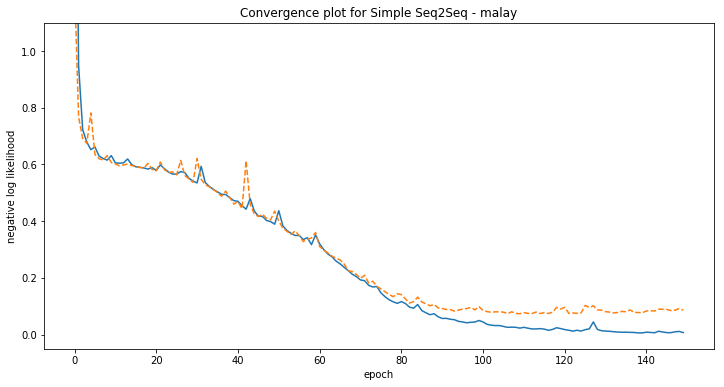
Some examples of model predictions:
-----------------------------------
satu 110
dua 31
tiga 3
sebelas 1110
lima belas 110
seratus tiga puluh dua 13
seratus ribu dua belas 1012
tujuh ribu lapan ratus lima puluh sembilan 7667
dua puluh satu 210
dua puluh empat 24
lapan puluh 87
sembilan puluh satu ribu 910
sembilan puluh satu ribu dua ratus dua 972
[malay] Phrase-level test accuracy is 0.028 when training with dataset size = 1000.
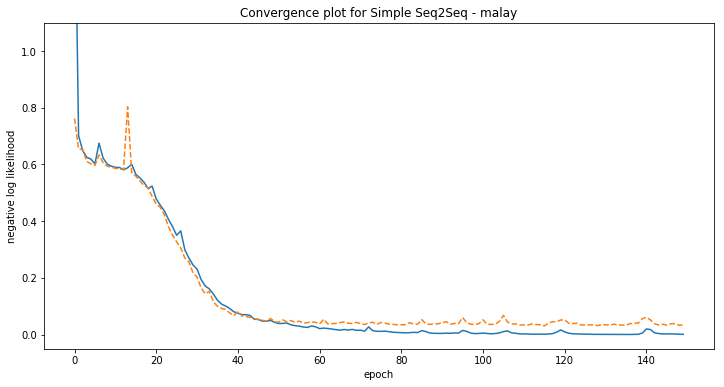
Some examples of model predictions:
-----------------------------------
satu 100
dua 200
tiga 100
sebelas 110
lima belas 151
seratus tiga puluh dua 122
seratus ribu dua belas 192
tujuh ribu lapan ratus lima puluh sembilan 7859
dua puluh satu 210
dua puluh empat 24
lapan puluh 8108
sembilan puluh satu ribu 9108
sembilan puluh satu ribu dua ratus dua 9222
[malay] Phrase-level test accuracy is 0.098 when training with dataset size = 2000.
Some examples of model predictions:
-----------------------------------
satu 101
dua 500
tiga 005
sebelas 111
lima belas 1501
seratus tiga puluh dua 132
seratus ribu dua belas 1012
tujuh ribu lapan ratus lima puluh sembilan 7859
dua puluh satu 210
dua puluh empat 204
lapan puluh 800
sembilan puluh satu ribu 91
sembilan puluh satu ribu dua ratus dua 91202
[malay] Phrase-level test accuracy is 0.466 when training with dataset size = 4000.
Some examples of model predictions:
-----------------------------------
satu 1010
dua 20
tiga 30
sebelas 1111
lima belas 1511
seratus tiga puluh dua 132
seratus ribu dua belas 10012
tujuh ribu lapan ratus lima puluh sembilan 7859
dua puluh satu 21
dua puluh empat 20
lapan puluh 80
sembilan puluh satu ribu 91000
sembilan puluh satu ribu dua ratus dua 91202
[malay] Phrase-level test accuracy is 0.964 when training with dataset size = 6000.
Some examples of model predictions:
-----------------------------------
satu 106
dua 20
tiga 30
sebelas 1111
lima belas 15
seratus tiga puluh dua 138
seratus ribu dua belas 100012
tujuh ribu lapan ratus lima puluh sembilan 7859
dua puluh satu 21
dua puluh empat 24
lapan puluh 80
sembilan puluh satu ribu 91000
sembilan puluh satu ribu dua ratus dua 91202
[malay] Phrase-level test accuracy is 0.995 when training with dataset size = 8000.

Some examples of model predictions:
-----------------------------------
satu 1
dua 20
tiga 30
sebelas 110
lima belas 15
seratus tiga puluh dua 132
seratus ribu dua belas 100012
tujuh ribu lapan ratus lima puluh sembilan 7859
dua puluh satu 20
dua puluh empat 24
lapan puluh 80
sembilan puluh satu ribu 91000
sembilan puluh satu ribu dua ratus dua 91202
[malay] Phrase-level test accuracy is 0.999 when training with dataset size = 12000.

Some examples of model predictions:
-----------------------------------
satu 1
dua 200
tiga 3
sebelas 1
lima belas 15
seratus tiga puluh dua 132
seratus ribu dua belas 100012
tujuh ribu lapan ratus lima puluh sembilan 7859
dua puluh satu 21
dua puluh empat 24
lapan puluh 80
sembilan puluh satu ribu 91000
sembilan puluh satu ribu dua ratus dua 91202
[malay] Phrase-level test accuracy is 0.980 when training with dataset size = 15000.

Some examples of model predictions:
-----------------------------------
satu 1
dua 2
tiga 3
sebelas 11
lima belas 15
seratus tiga puluh dua 132
seratus ribu dua belas 100012
tujuh ribu lapan ratus lima puluh sembilan 7859
dua puluh satu 21
dua puluh empat 24
lapan puluh 80
sembilan puluh satu ribu 91000
sembilan puluh satu ribu dua ratus dua 91202
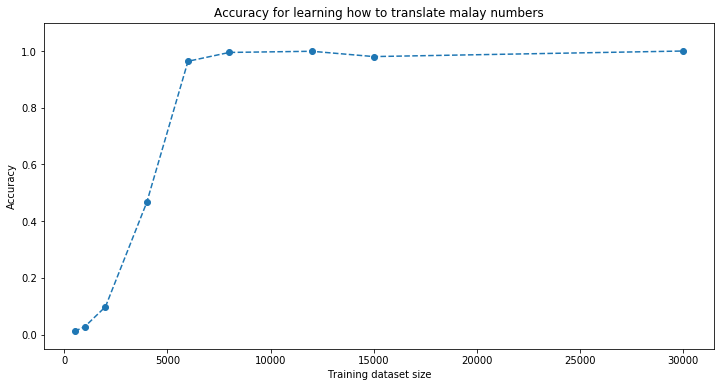
[malay] Phrase-level test accuracy is 1.000 when training with dataset size = 30000.
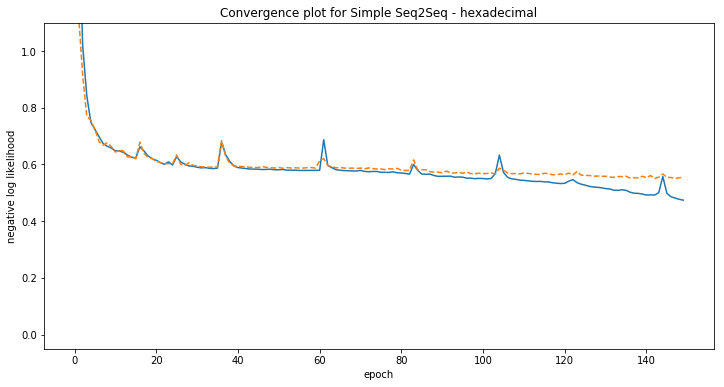
Some examples of model predictions:
-----------------------------------
1 17
2 17
3 13
B 12
F 12
84 17
186AC
1EB3 1
15 17
18 17
50 13
16378 1
16442
[hexadecimal] Phrase-level test accuracy is 0.000 when training with dataset size = 500.
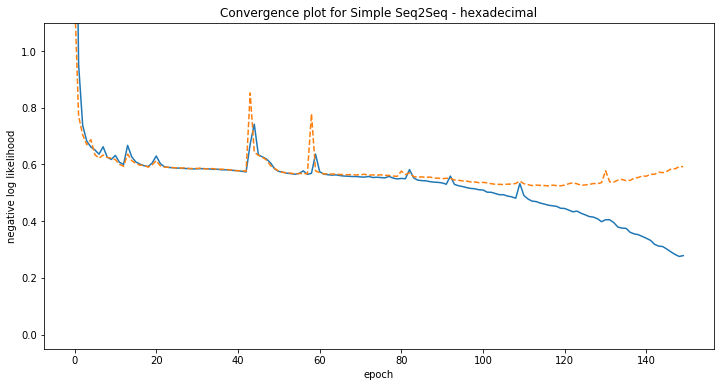
Some examples of model predictions:
-----------------------------------
1
2
3
B
F
84
186AC
1EB3
15
18
50
16378
16442
[hexadecimal] Phrase-level test accuracy is 0.000 when training with dataset size = 1000.
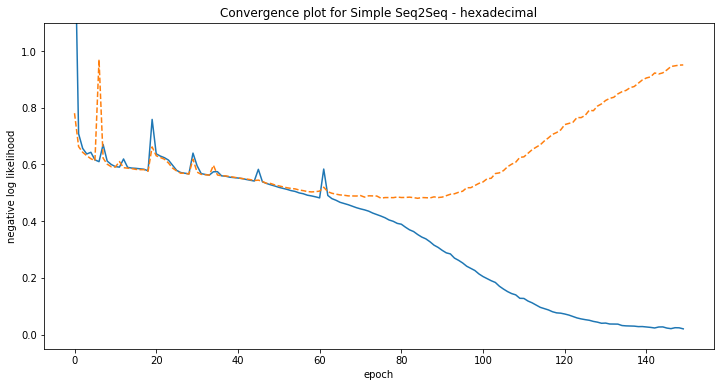
Some examples of model predictions:
-----------------------------------
1 3
2 82
3 13717
B 2
F 2
84 2128
186AC
1EB3
15 3
18 23
50 2
16378
16442
[hexadecimal] Phrase-level test accuracy is 0.000 when training with dataset size = 2000.
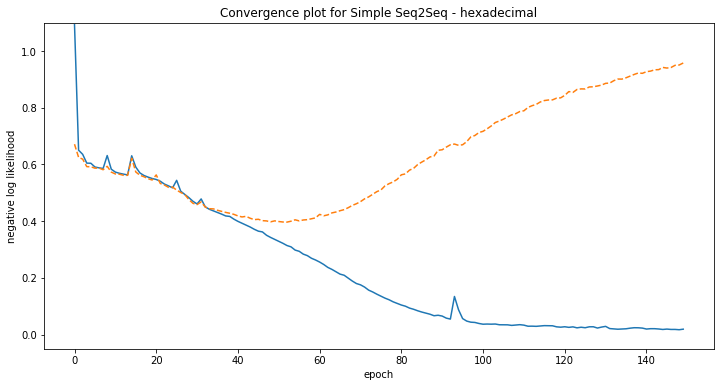
Some examples of model predictions:
-----------------------------------
1
2
3 B
B
F
84
186AC
1EB3
15
18
50
16378
16442
[hexadecimal] Phrase-level test accuracy is 0.000 when training with dataset size = 4000.
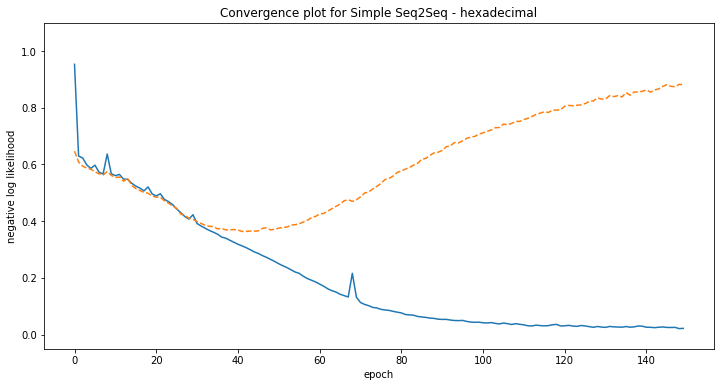
Some examples of model predictions:
-----------------------------------
1
2
3
B
F
84
186AC
1EB3
15
18
50
16378
16442
[hexadecimal] Phrase-level test accuracy is 0.000 when training with dataset size = 6000.
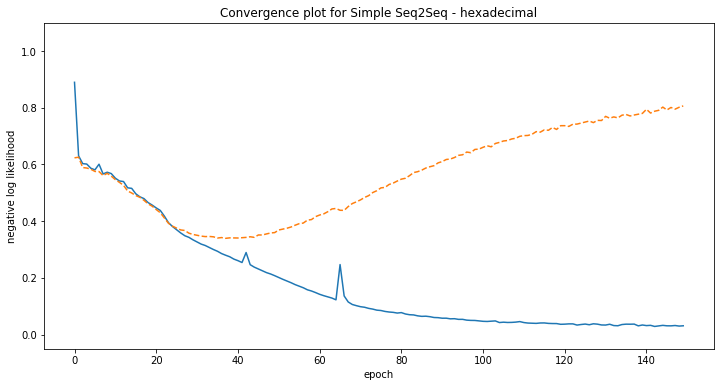
Some examples of model predictions:
-----------------------------------
1
2
3
B
F
84
186AC
1EB3
15
18
50
16378
16442
[hexadecimal] Phrase-level test accuracy is 0.000 when training with dataset size = 8000.
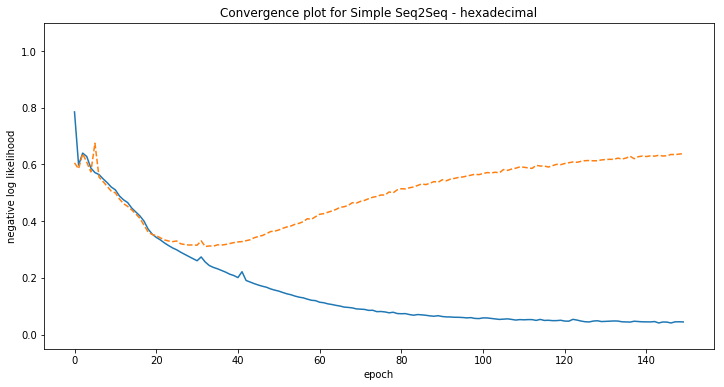
Some examples of model predictions:
-----------------------------------
1 6
2 9
3 2
B 4
F 6
84 3
186AC
1EB3
15
18
50 2
16378
16442
[hexadecimal] Phrase-level test accuracy is 0.000 when training with dataset size = 12000.
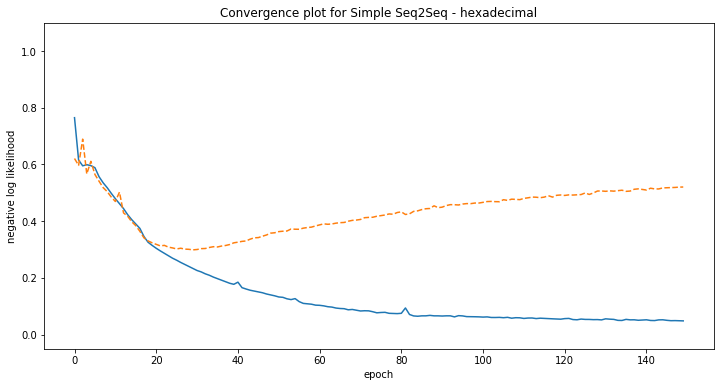
Some examples of model predictions:
-----------------------------------
1 1
2 70
3 7
B 1
F 4
84 2
186AC
1EB3 457
15
18
50 6
16378
16442
[hexadecimal] Phrase-level test accuracy is 0.000 when training with dataset size = 15000.
Some examples of model predictions:
-----------------------------------
1 1
2 7
3 6
B 1
F 2
84
186AC
1EB3
15 3
18 6
50 8
16378
16442
[hexadecimal] Phrase-level test accuracy is 0.000 when training with dataset size = 30000.

# display the accuracy curve as function of the train size
plt.figure(figsize=(12, 6))
for language in languages:
plt.plot(list(accuracy[language].keys()),
list(accuracy[language].values()),
'--o',
label=language)
plt.ylabel('Accuracy')
plt.xlabel('Training dataset size')
plt.title('Accuracy for learning how to translate numbers')
plt.ylim([-0.05, 1.1])
plt.legend()
plt.show()