[HKML] Hong Kong Machine Learning Meetup Season 1 Episode 5
[HKML] Hong Kong Machine Learning Meetup Season 1 Episode 5
When?
- Wednesday, December 19, 2018 from 7:00 PM to 9:00 PM
Where?
- Prime Insight, 3 Lockhart Road, Wan Chai, Hong Kong
This meetup was sponsored by Prime Insight which offered the location, drinks and snacks. Thanks to them, and in particular to Romain Haimez and Matthieu Pirouelle.
Programme:
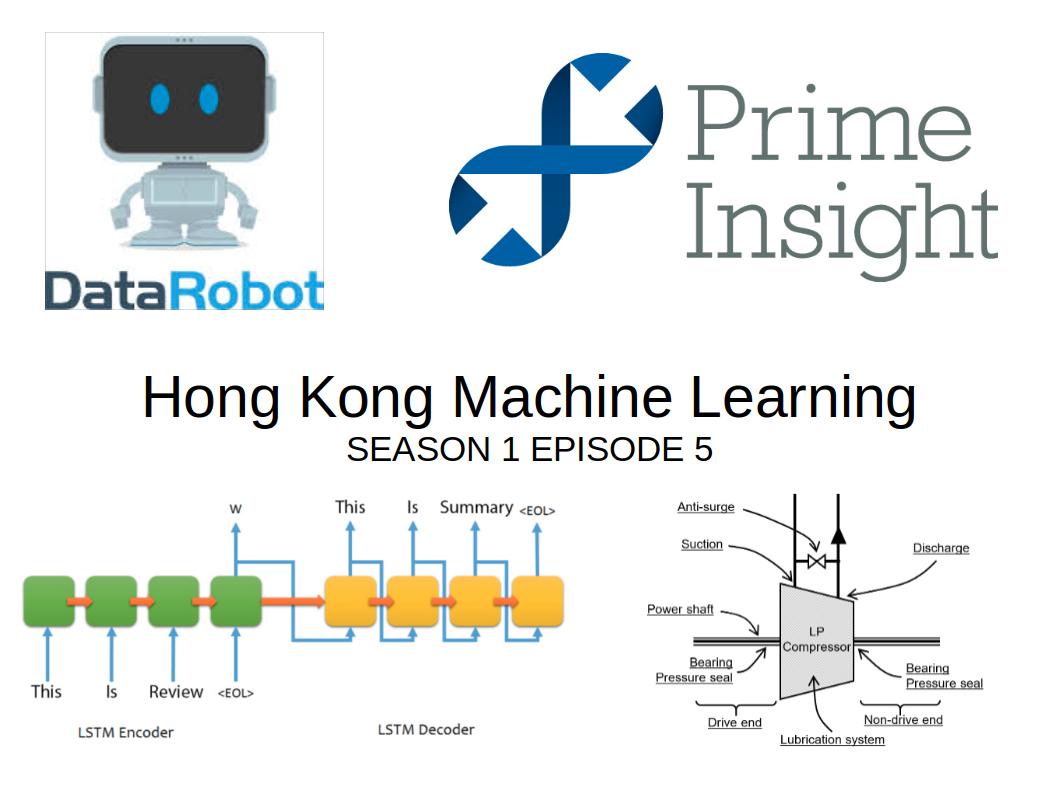
Nathan presented his graduate research work at MIT: Abstractive Summarization of Unstructured Text. As usual in these meetups, speakers stay away from the media hype to present the real state of the art, and Nathan was no exception. He explained that the current approach which is composed of many steps relies on many assumptions and short cuts. Moreover each of these steps introduces noise, e.g. optical character recognition (OCR) is not perfect yet. After all the text and image preprocessing is done (itself relying on deep learning components) starts the deep learning modelling of interest: an end-to-end approach is still out of practical reach considering the available amount of data for his problem (not much) and lack of labels. The approach essentially consists in using a Sequence to Sequence with Attention model. However, a couple of problems arise in the abstractive summarization task, e.g. for “Germany emerge victorious in 2-0 win against Argentina on Saturday …”:
-
Not abstracting important details Won by ‘2-3’ instead of ‘3-2’
-
Repetitions ‘Germany beat Germany beat Germany beat…’
-
Higher-Level Abstraction — words generated almost always come directly from text
-
Importance of sentences — what to summarize in larger documents.
-
Incorrect Composition of Fragments — ‘Argentina beat Germany’
-
Misuse of pronouns
Nathan walked us through on how to alleviate these shortcomings (cf. his slides) by leveraging refined models, e.g. Get to the Point: Summarization with Pointer-Generators, its associated code and blog.
Timothy, working for Centrica, the largest supplier of gas to domestic customers in the United Kingdom, introduced us to the challenges in this industry, and how machine learning can help to tackle them. In his presentation, Basically, the gas compressors are complex and large-scale industrial systems that are real-time monitored through thousand of sensors. A standard typical approach is to have hard-coded rules that trigger alerts when some physical value, e.g. temperature or pressure, is beyond some critical threshold. His research question: Can we determine the underlying operating states of the process? To do so, he encodes the multivariate time series into a state (context) vector using a RNN (LSTM) encoder-decoder model. Once this context vector is obtained, its evolution is the main object of study. The trajectory of this vector through time allows to identify the different operating states as if nothing changes the vector would stay in the same neighbourhood over many timesteps, and would move to another neighbourhood if something changes. It would drift there more or less quickly depending on the abruptness of the regime change.
Personal note: It reminded me some work I did with correlation matrices of financial time series: Each correlation matrix (estimated on a rolling window) is a vector living in the elliptope (the space of correlation matrices); Usually, (can be visualized in 3D for 3 assets) the vector would stay in the same region of the space for some time, then move to some other region and stays there for a while, etc. The technique Timothy presented might be useful to detect regime shifts, aka structural breaks in econometrics, as a non-linear alternative to the linear econometrics toolbox.
Alexandre talked about the recurrent problem in the industry of dataset shift, i.e. the distribution used to fit the model is different from the distribution when applying it. Consequences of a dataset shift can be particularly dramatic in the case of healthcare, insurance and retail banking (loan attribution). Alexandre focused on a particular case of dataset shift, the covariate shift. Covariate shift corresponds to the case where the conditional distribution of the output given the input doesn’t change, but the marginal distribution of the input does. For example, more old people in the training set whereas more young people in the test set (due to demographic change or bias in the sampling for building the training set). Alexandre also presented us a couple of methods to identify dataset shift: statistical distance, novelty detection, discriminative distance (cf. his slides for more details). Finally, once a covariate shift is detected, one may want to correct it. One way to do so is to reweight the points of the training set so that the points which are very similar to those in the testing set get more weight (cf. this blog for the technical details). Alexandre ended his presentation by showcasing how these techniques are implemented in the DataRobot solution, which is a platform that automates the machine learning pipeline.