Experimenting with LIME - A tool for model-agnostic explanations of Machine Learning models
Experimenting with LIME - A tool for model-agnostic explanations of Machine Learning models
I recently became aware of the LIME tool thanks to Alexandre Gerbeaux from DataRobot who did a presentation on machine learning models interpretability at the last Hong Kong Machine Learning Meetup.
LIME stands for Local Interpretable Model-agnostic Explanations, an important topic for both academic research and practitioners in sensitive industries (e.g. medicine, healthcare, finance).
Basically, the LIME approach approximates locally (in the vicinity of the sample under study) the complex machine learning model. There is a trade-off between accuracy and explainability that can be cast as an optimization problem. Inside a subclass of very simple models with not too much parameters, LIME finds the best approximator. Parameters of this “best” simple approximator are then displayed to the user.
For more details, please refer to the LIME paper: “Why Should I Trust You?” Explaining the Predictions of Any Classifier. There is even a YouTube Video! And a GitHub repo.
Below, we will continue playing with the DataGrapple blogs and the toy-sentiment model described in these two previous blogs: blog 1, blog 2.
In short, we obtained a generative model using the Snorkel tool that can produce noisy labels (based on a few expert rules). We can use these noisy labels to train a machine learning model that works directly on the raw content. In this blog, we will use a basic off-the-scikit-learn-shelf Random Forest. In a future experiment, we will apply LIME to BERT.
%matplotlib inline
import re
import pickle
import numpy as np
import pandas as pd
from scipy import sparse
import sklearn
import sklearn.ensemble
import sklearn.metrics
from sklearn.metrics import confusion_matrix, f1_score
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
from metal.label_model import LabelModel
from metal.analysis import lf_summary, label_coverage
from metal.label_model.baselines import MajorityLabelVoter
from lime import lime_text
with open('./blogs', 'rb') as file:
blogs = pickle.load(file)
print("We consider for the in-sample", len(blogs), "blogs.")
blogs = pd.DataFrame([blog['title'].replace('\t', '')
+ ' ' + blog['content'].replace('\t', '').replace('\n', '').replace('\r', '')
for blog in blogs],
index = [i for i in range(len(blogs))])
/home/gmarti/anaconda3/lib/python3.6/site-packages/sklearn/ensemble/weight_boosting.py:29: DeprecationWarning: numpy.core.umath_tests is an internal NumPy module and should not be imported. It will be removed in a future NumPy release.
from numpy.core.umath_tests import inner1d
We consider for the in-sample 1238 blogs.
blogs.head()
| 0 | |
|---|---|
| 0 | That Is A Big Deal In a decently risk-on sessi... |
| 1 | Only Game In Town Today, the ECB pretty much d... |
| 2 | Impairment Bites HEMA (short for 4 unpronounce... |
| 3 | On The Red Today the 5y CDS of Crown Resorts L... |
| 4 | Shipping Names Rocked Today CMA CGM (CMACG) an... |
ABSTAIN = 0
POSITIVE = 1
NEGATIVE = 2
def vader_sentiment(text):
analyzer = SentimentIntensityAnalyzer()
vs = analyzer.polarity_scores(text)
if vs['compound'] > 0.8:
return POSITIVE
elif vs['compound'] < -0.8:
return NEGATIVE
else:
return ABSTAIN
PERFORMING = r"""\b(\d+bps tighter|tighter by \d+bp|credit spreads tighten across the board|back to the lowest spread level|CDS tightens back|little appetite to bid for single-name protection|stock up|strong performance|spreads tightening|performed|tighter|tighten|beating expectations|best performers|best performing|outperformance|outperforming|outperformer|outperformers)"""
def contains_performing_expressions(text):
return POSITIVE if re.search(PERFORMING, text) else ABSTAIN
GOOD_RATINGS = r"\b(S&P upgraded|upgrade|upgraded|upgraded by Fitch|upgraded by Moody's)"
def contains_upgrade_expressions(text):
return POSITIVE if re.search(GOOD_RATINGS, text) else ABSTAIN
GOOD_MOODS = r"\b(reassured credit investors|good short-term option|risk-on|positively in credit|dovish|guidance was positive|good for credit|issues have been pushed back|bullish)"
def contains_good_mood_expressions(text):
return POSITIVE if re.search(GOOD_MOODS, text) else ABSTAIN
GOOD_LIQUIDITY = r"\b(resolve the liquidity issue)"
def contains_good_liquidity_expressions(text):
return POSITIVE if re.search(GOOD_LIQUIDITY, text) else ABSTAIN
BAD_MOODS = r"\b(risk-off|tough test|disappointed|continued deterioration|challenging for credit|brutal punishment|hawkish|profit warning|dampen credit outlook|bearish)"
def contains_bad_mood_expressions(text):
return NEGATIVE if re.search(BAD_MOODS, text) else ABSTAIN
UNDERPERFORMING = r"""\b(cut its profit forecast|stocks fall|higher leverage|shares plunged|widened \d+bp|CDS widened c\d+bp|bonds fell roughly \d+pts|stock got crushed|quarterly profit miss|shares sunk|loses money|risk premium through the roof|stock lost|revenues declined|downtrend in revenue|Q[1-4] results missed|bonds were trashed|defaulted on its debt|survival of the company is under threat|lost its leadership|Q[1-4] sales missed|weaker demand|sales down|stocks declined|bid single-name protection|weakens credit metrics|profit warnings|guidance dropped|missed the estimates|worst-performing|widening|underperformers|widen +\d+bp|under more pressure|curve is inverted|worst performing|CDS is wider|underperforming|underperformed|bonds were down|CDS widen by c\d+bp)"""
def contains_underperforming_expressions(text):
return NEGATIVE if re.search(UNDERPERFORMING, text) else ABSTAIN
BAD_RATINGS = r"\b(Fitch downgraded|outlook to negative|downgrade|downgraded|outlook at negative)"
def contains_downgrade_expressions(text):
return NEGATIVE if re.search(BAD_RATINGS, text) else ABSTAIN
FRAUDS = r"\b(money laundering|scandal)"
def contains_fraud_expressions(text):
return NEGATIVE if re.search(FRAUDS, text) else ABSTAIN
DEFAULTS = r"\b(filed for bankruptcy|chapter 11|filed for creditor protection|continue as a going concern)"
def contains_default_expressions(text):
return NEGATIVE if re.search(DEFAULTS, text) else ABSTAIN
BAD_MOMENTUM = r"\b(risk premium has tripled)"
def contains_bad_momentum_expressions(text):
return NEGATIVE if re.search(BAD_MOMENTUM, text) else ABSTAIN
CATASTROPHE = r"\b(devastating impact|struck by hurricane)"
def contains_catastrophe_expressions(text):
return NEGATIVE if re.search(CATASTROPHE, text) else ABSTAIN
LFs = [
vader_sentiment,
contains_performing_expressions,
contains_upgrade_expressions,
contains_good_mood_expressions,
contains_good_liquidity_expressions,
contains_underperforming_expressions,
contains_downgrade_expressions,
contains_bad_mood_expressions,
contains_fraud_expressions,
contains_default_expressions,
contains_bad_momentum_expressions,
contains_catastrophe_expressions,
]
LF_names = [
'vader',
'performing',
'upgrade',
'good_mood',
'good_liquidity',
'underperforming',
'downgrade',
'bad_mood',
'fraud',
'default',
'bad_momentum',
'catastrophe',
]
def make_Ls_matrix(data, LFs):
noisy_labels = np.empty((len(data), len(LFs)))
for i, row in data.iterrows():
for j, lf in enumerate(LFs):
noisy_labels[i][j] = lf(row.values[0].lower())
return noisy_labels
with open('labels_for_training_labelling', 'rb') as file:
labels = pickle.load(file)
LF_matrix = make_Ls_matrix(blogs.iloc[:len(labels)], LFs)
Y_LF_set = np.array([labels[i] for i in range(len(labels))])
Ls_train = make_Ls_matrix(blogs, LFs)
label_model = LabelModel(k=2, seed=42)
label_model.train_model(Ls_train,
Y_dev=Y_LF_set,
n_epochs=1000,
lr=0.01,
log_train_every=2000)
Computing O...
Estimating \mu...
Finished Training
Ls_train = make_Ls_matrix(blogs, LFs)
Y_train_ps = label_model.predict_proba(Ls_train)
Y_train_ps
array([[0.79409309, 0.20590691],
[0.34469373, 0.65530627],
[0.45152156, 0.54847844],
...,
[0.25849666, 0.74150334],
[0.59675846, 0.40324154],
[0.76897848, 0.23102152]])
Fit of a Random Forest based on the noisy training labels provided by Snorkel
class_names = ['POSITIVE', 'NEGATIVE']
vectorizer = TfidfVectorizer(lowercase=False)
train_vectors = vectorizer.fit_transform(list(blogs[0].values))
test_vectors = vectorizer.transform(list(blogs[0].values))
rf = sklearn.ensemble.RandomForestClassifier(n_estimators=500)
rf.fit(train_vectors, np.argmax(Y_train_ps, axis=1))
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=500, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False)
pred = rf.predict(test_vectors)
sklearn.metrics.f1_score(np.argmax(Y_train_ps, axis=1), pred, average='binary')
1.0
The Random Forest has fitted perfectly the training set. Overfitting?
Instead of evaluating on an independent test set as it is the standard practice, we will explore the interpretability of the model with LIME to judge if it is a blatant case of overfitting or not.
c = make_pipeline(vectorizer, rf)
idx = 0
print("Proba predicted by the Random Forest:", c.predict_proba([blogs[0].values[idx]])[0])
print("Proba predicted by Snorkel labeler (for training):", Y_train_ps[idx])
Proba predicted by the Random Forest: [0.844 0.156]
Proba predicted by Snorkel labeler (for training): [0.79409309 0.20590691]
blogs[0].values[idx]
'That Is A Big Deal In a decently risk-on session (CDX IG -2.8 CDX HY -8.9 SPX @ 2,900), the CDS of Anadarko Petroleum Corp. (APC) outperformed the broader market, tightening by c65bp. Bonds are also 75-100bp tighter. That is because the oil giant Chevron Corp. (CVX) agreed to buy APC. The equity is valued $33B, which will be paid in stocks and cash (75/25: 0.3869 CVX shares and $16.25 in cash per APC share). That is a 39% premium therefore APC share soared towards the offer price (+23% on day). The transaction is expected to close in 2H19. CVX management doesn’t expect any regulatory issues. From a credit standpoint, CVX will assume $15B net debt from APC, making APC EV c$50B. CVX will issue 200M shares and pay $8B in cash. A very tight name, CVX widened 6bp to 33bp mid, making the APC/CVX spread tighten 71bp, from +70bp to -1bp! CVX is not really a story for credit. Indeed, CVX has c$9.4B cash on hand and past experience proves that it generates $8B+ FCF per year at $50-55/bbl crude (vs now WTI $64), so it looks unlikely that they will fund the non-share cash part (c$8B) with debt. And even in the unlikely event it would do that, the combined leverage would be somewhere around 1x. Adding to this point, the news that 1/ CVX expects to realize $2B synergies (proceeds partly used for debt reduction) 2/ CVX plans to sell $15-20bn of assets in 2020-2022 confirms that CVX credit is not in trouble anytime soon. Therefore the consensus expects CVX to keep its current rating (AA/Aa2), while APC will converge to CVX from its Ba1/BBB, although we don’t know if CVX will explicitly guarantee them. CVX aside, this news dragged all the US/Canada IG energy tighter, with Hess -22 Devon -15 Encana -13, partly because the market knew APC was a target and consolidation was expected. This acquisition shows the importance of size in this business, where the biggest and the most diversified players do well. '
Explore the important features using LIME toolbox
from lime.lime_text import LimeTextExplainer
explainer = LimeTextExplainer(class_names=['POSITIVE', 'NEGATIVE'])
indices = [0, 500, 700, 1100, 600, 65, 627, 114, 858, 50, 52, 757, 190, 769, 47]
for idx in indices:
exp = explainer.explain_instance(blogs[0].values[idx], c.predict_proba, num_features=6)
print('Document id: %d' % idx)
print('Probability(POSITIVE) =', c.predict_proba([blogs[0].values[idx]])[0,0])
print('Probability(NEGATIVE) =', c.predict_proba([blogs[0].values[idx]])[0,1])
print("Main features:")
for feature in exp.as_list():
print(feature)
print('\nOriginal prediction:', rf.predict_proba(test_vectors[idx])[0,1])
tmp = test_vectors[idx].copy()
tmp[0, vectorizer.vocabulary_[exp.as_list()[0][0]]] = 0
tmp[0, vectorizer.vocabulary_[exp.as_list()[1][0]]] = 0
print('Prediction removing the two most important features:', rf.predict_proba(tmp)[0,1])
print('Difference:', round(rf.predict_proba(tmp)[0,1] - rf.predict_proba(test_vectors[idx])[0,1], 3))
exp.show_in_notebook(text=True)





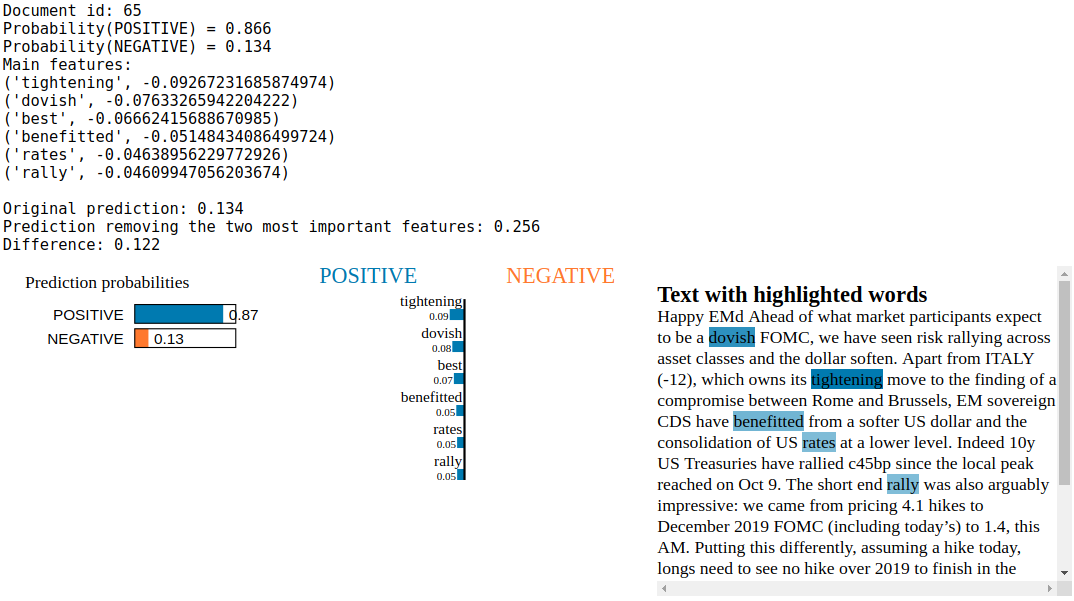









Conclusion: The Random Forest classifier seems largely overfitted: “Mr”, “Draghi”, “PEMEX”, “Volkswagen”, “TOSH”, “TITIM”, “CDX”, “ECB” being highlighted as important features to explain locally the behaviour of the Random Forest indicates that the model overfitted on a few tickers and proper nouns. The fact that the ECB, with Mr Draghi, was dovish during the period these blogs were written has tricked the model into believing that any apparition of “ECB” or “Draghi” in a text is positive news for credit spreads. On the positive side, the model seems to have picked up the importance of “tightening” and “downgrade” with respect to the credit sentiment.
Notice that the simple “expert rules” composed of dictionary, string matching, regular expressions and VADER didn’t see these particular tokens and didn’t input this information into the Snorkel labeler. The Snorkel labeler is only a model to label data at scale so that powerful models that work on the raw data can be trained, and, very likely, will outperform the Snorkel labeler itself.
In this particular case, it is not the case. The Snorkel labeler is superior. The model trained on raw data has very high chance of overfitting to trends (e.g. “Draghi” means positive, “PEMEX” means negative), and will break down out-of-sample once the trend changes.
To avoid this pitfall, the raw text needs further pre-processing: POS and NER tagging to remove proper nouns, tickers, companies and other organizations that may confuse the supervised model.