Selected ML Papers from ICML 2023

Selected ML Papers from ICML 2023
This blog post serves as a summary and exploration of ~100 papers, providing insights into the key trends presented at ICML 2023. The papers can be categorized into several sub-fields, including Graph Neural Networks and Transformers, Large Language Models, Optimal Transport, Time Series Analysis, Causality, Clustering, PCA and Autoencoders, as well as a few miscellaneous topics.
Graph Neural Networks and Transformers
The first sub-field, Graph Neural Networks and Transformers, encompasses papers that delve into the fusion of graph theory and deep learning architectures. These papers explore novel methods to enhance the representation and understanding of complex graph-structured data. They aim to improve graph reasoning, graph generation, and graph embedding techniques, unlocking the potential for more accurate predictions and insights.
Transformers Meet Directed Graphs
Transformers as Algorithms: Generalization and Stability in In-context Learning
Fast Inference from Transformers via Speculative Decoding
One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
Graph Inductive Biases in Transformers without Message Passing
On the Connection Between MPNN and Graph Transformer
Towards Understanding the Generalization of Graph Neural Networks
Graph Generative Model for Benchmarking Graph Neural Networks
XTab: Cross-table Pretraining for Tabular Transformers
Feature Expansion for Graph Neural Networks
Fisher Information Embedding for Node and Graph Learning
GOAT: A Global Transformer on Large-scale Graphs
Coder Reviewer Reranking for Code Generation
Exphormer: Sparse Transformers for Graphs
Distribution Free Prediction Sets for Node Classification
Node Embedding from Neural Hamiltonian Orbits in Graph Neural Networks
Relevant Walk Search for Explaining Graph Neural Networks
Quantifying the Knowledge in GNNs for Reliable Distillation into MLPs
Conformal Prediction Sets for Graph Neural Networks
Leveraging Label Non-Uniformity for Node Classification in Graph Neural Networks
Large Language Models
Large Language Models have gained significant attention in recent years for their ability to generate coherent and contextually relevant text. The papers in this sub-field delve into the advancements and challenges related to these models. They address topics such as fine-tuning strategies, model interpretability, long-tail knowledge learning, efficiency at inference time, and exploring the limits and biases of language models.
POUF: Prompt-Oriented Unsupervised Fine-tuning for Large Pre-trained Models
Very interesting paper for practical applications… Simple but neat idea of aligning the distributions between the unlabeled target data (potentially very different than the data on which the model was pre-trained) and textual prototypes (prompts) using a fine-tuning loss based on optimal transport and mutual information.
Why do Nearest Neighbor Language Models Work?
Prompting Large Language Model for Machine Translation: A Case Study
Large Language Models Struggle to Learn Long-Tail Knowledge
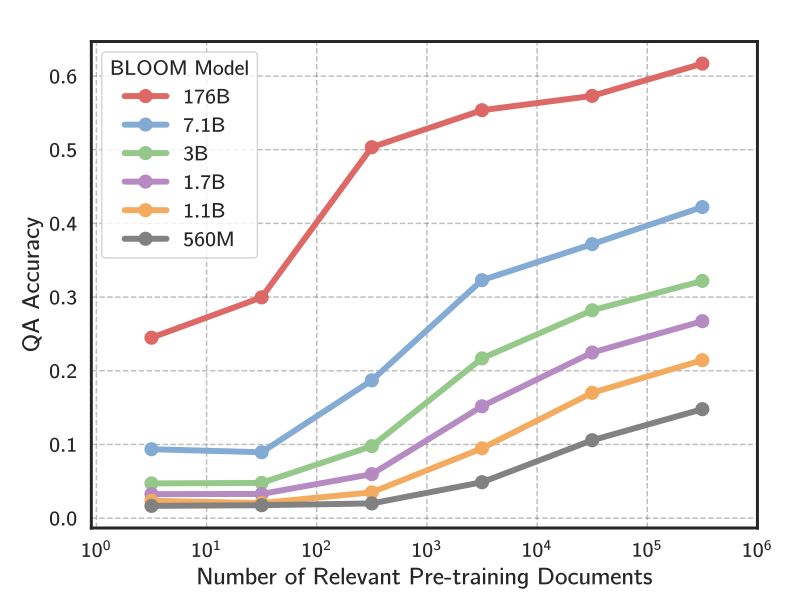
Interesting empirical study showing the correlation (and causality) between the number of relevant pre-training documents and the Question & Answer accuracy of Large Language Models.
In short, the more documents covering the topic (question, answer), the better.
-
Having larger LMs helps (R^2 98%) but log-linear scaling make it unrealistic for now as a serious improvement direction;
-
Adding a retrieval module (prompt enriched by relevant context) boosts answers’ accuracy on low resource questions, and seems a more promising research direction.
-
Authors focus on absolute counts of relevant documents, but what about ratios (wrt other topics in the corpus)?
-
How is the Q&A accuracy impacted by contradicting documents on facts as a function of their ratios?
-
Is the majority view always winning? Does it depend on the ratio? Or more contextual?
Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time
Tuning Language Models as Training Data Generators for Augmentation-Enhanced Few-Shot Learning
Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning
SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
Can Large Language Models Reason about Program Behavior?
Outline, Then Details: Syntactically Guided Coarse-To-Fine Code Generation
Large Language Models Can Be Easily Distracted by Irrelevant Context
DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature
Simple but interesting idea!
This paper poses a simple hypothesis: minor rewrites of model-generated text tend to have lower log probability under the model than the original sample, while minor rewrites of human-written text may have higher or lower log probability than the original sample.
We empirically verify this hypothesis, and find that it holds true across a diverse body of LLMs, even when the minor rewrites, or perturbations, come from alternative language models.
FlexGen: High-throughput Generative Inference of Large Language Models with a Single GPU
CodeIPPrompt: Intellectual Property Infringement Assessment of Code Language Models
The Unreasonable Effectiveness of Few-shot Learning for Machine Translation
Repository-Level Prompt Generation for Large Language Models of Code
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
“Models as Data” contribution to the literature and future research effort.
The Pythia suite is the only publicly released suite of LLMs that satisfies three key properties:
- Models span several orders of magnitude of model scale.
- All models were trained on the same data in the same order.
- The data and intermediate checkpoints are publicly available for study.
Specializing Smaller Language Models towards Multi-Step Reasoning
Knowledge distillation of code-davinci-002 to tune smaller FlanT5:
Specializing T5 and FlanT5 from a code-davinci-002 to have a chain-of-thought (CoT) ability on math problems.
CoT typically appears for large language models (> 100B) but cannot be found in small models. This paper shows a way to obtain specialized CoT in small models, but at the expense of losing generic abilities.
In this paper, authors have to face the misalignment between the GPT tokenizer and the T5 tokenizer. They solve it by using dynamic programming.
Authors use the following datasets:
- GSM8K
- MultiArith GitHub repo with json dataset
- ASDiv GitHub repo with the xml dataset
- SVAMP GitHub repo with json dataset
Besides this math CoT, what are others specializations one might want to try?
We show the importance of using the instruction-tuned checkpoints as the base model because their generalization performance is better than the raw pretrained checkpoints.
Automatically Auditing Large Language Models via Discrete Optimization
Pretraining Language Models with Human Preferences
LEVER: Learning to Verify Language-to-Code Generation with Execution
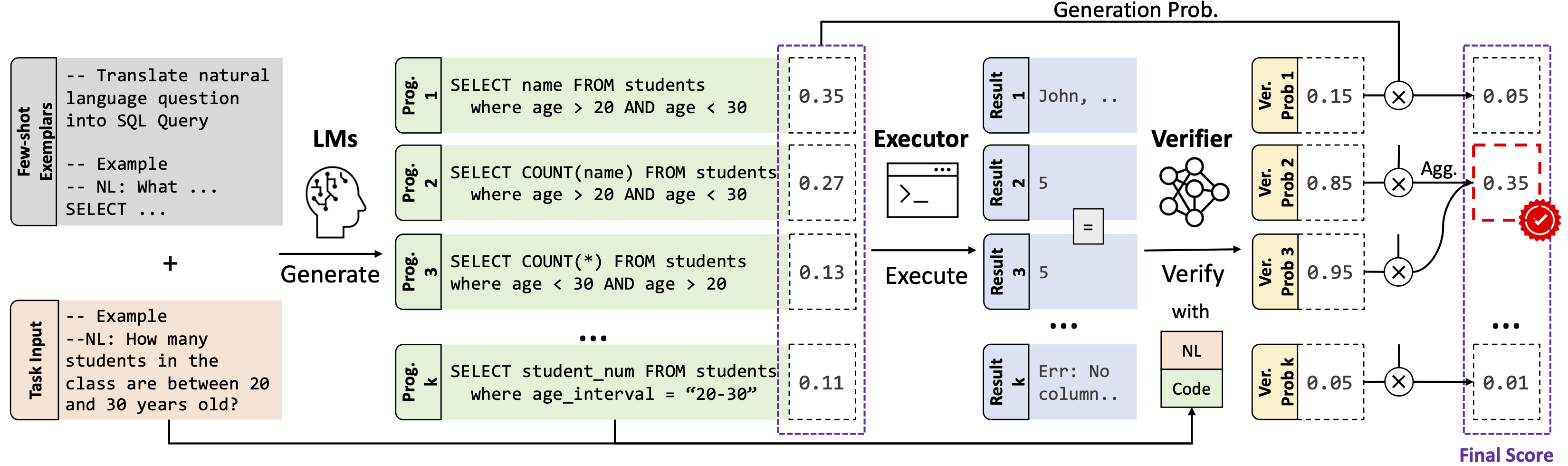
Well motivated approach: (Code)Language Models (CodeLMs) are costly to finetune; Authors propose an approach to improve them (e.g. OpenAI Codex) without changing their parameters.
Train a Verifier (much smaller LM, 0.5% of the CodeLM original size) to classify whether a triplet: (code in natural language, corresponding code generated by the CodeLM, output obtained by executing the LM-generated code) is correct or not.
Then, take the argmax of the combined CodeLM proba x verification probability from small LM, voila!
Through various empirical studies, authors show it is better to combine both probabilities than doing pruning (thresholding, binary decisions), and that both probabilities are calibrated very differently: The Verifier (small classification LM) being better at detecting obvious mistakes leading to faulty executions, where the OG CodeLM being better at distinguishing amongst the top-ranked programs.
Not too dissimilar to diversification and alpha combination in quant.
Synthetic Prompting: Generating Chain-of-Thought Demonstrations for Large Language Models
Same Pre-training Loss, Better Downstream: Implicit Bias Matters for Language Models
Effective Structured Prompting by Meta-Learning and Representative Verbalizer
Text Generation with Diffusion Language Models: A Pre-training Approach with Continuous Paragraph Denoise
Optimal Transport
The field of Optimal Transport deals with the study of transportation and mapping between probability distributions. The papers in this sub-field propose new methods and insights into utilizing Optimal Transport for various ML tasks, including generative modeling, information maximization, and embedding high-dimensional features.
Monge, Bregman and Occam: Interpretable Optimal Transport in High-Dimensions with Feature-Sparse Maps
InfoOT: Information Maximizing Optimal Transport
Meta Optimal Transport
Linear Optimal Partial Transport Embedding
Time Series
Time Series Analysis is crucial in understanding and predicting temporal data patterns. The papers in this sub-field introduce innovative techniques for time series forecasting, explainability of predictions, and handling feature and label shifts in domain adaptation scenarios.
Learning Deep Time-index Models for Time Series Forecasting
Learning Perturbations to Explain Time Series Predictions
Domain Adaptation for Time Series Under Feature and Label Shifts
Causality
Causal relationships play a fundamental role in understanding cause and effect in ML models. The papers in this sub-field explore metrics, algorithms, and frameworks for inferring and utilizing causal knowledge. They aim to enhance regression models with causal insights, generate counterfactual explanations, and uncover data manifolds entailed by structural causal models.
New metrics and search algorithms for weighted causal DAGs
Returning The Favour: When Regression Benefits From Probabilistic Causal Knowledge
High Fidelity Image Counterfactuals with Probabilistic Causal Models
On Data Manifolds Entailed by Structural Causal Models
Clustering
Clustering algorithms, Principal Component Analysis (PCA), and Autoencoders are essential tools for unsupervised learning and dimensionality reduction. The papers in this sub-field propose novel approaches for interpretable neural clustering, orthogonal-enforced latent spaces, structured variational autoencoders, and fundamental limits of two-layer autoencoders.
XAI Beyond Classification: Interpretable Neural Clustering
Multi-class Graph Clustering via Approximated Effective p-Resistance
End-to-end Differentiable Clustering with Associative Memories
PCA and Autoencoders
Extending Kernel PCA through Dualization: Sparsity, Robustness and Fast Algorithms
Orthogonality-Enforced Latent Space in Autoencoders: An Approach to Learning Disentangled Representations
Revisiting Structured Variational Autoencoders
Fundamental Limits of Two-layer Autoencoders, and Achieving Them with Gradient Methods
Misc.
Additionally, there are papers that cover a diverse range of topics. These include advancements in quantile regression, probabilistic attention models for event sequences, robust consensus ranking, synthetic data generation, model calibration, intellectual property infringement assessment, and more.
Faith-Shap: The Faithful Shapley Interaction Index
Flexible Model Aggregation for Quantile Regression
Probabilistic Attention-to-Influence Neural Models for Event Sequences
When does Privileged information Explain Away Label Noise?
Temporal Label Smoothing for Early Event Prediction
Simplifying Momentum-based Positive-definite Submanifold Optimization with Applications to Deep Learning
Never mind the metrics—what about the uncertainty? Visualising confusion matrix metric distributions
A Simple Zero-shot Prompt Weighting Technique to Improve Prompt Ensembling in Text-Image Models
Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models
A Large-Scale Study of Probabilistic Calibration in Neural Network Regression
Trompt: Towards a Better Deep Neural Network for Tabular Data
Synthetic Data, Real Errors: How (Not) to Publish and Use Synthetic Data
Nonlinear Advantage: Trained Networks Might Not Be As Complex as You Think
On the Power of Foundation Models
Git-Theta: A Git Extension for Collaborative Development of Machine Learning Models
Improving Expert Predictions with Conformal Prediction
Robust Consensus in Ranking Data Analysis: Definitions, Properties and Computational Issues
BEATs: Audio Pre-Training with Acoustic Tokenizers
Great Models Think Alike: Improving Model Reliability via Inter-Model Latent Agreement
A New PHO-rmula for Improved Performance of Semi-Structured Networks
Taxonomy-Structured Domain Adaptation
Explainability as statistical inference
Discrete Key-Value Bottleneck
End-to-End Multi-Object Detection with a Regularized Mixture Model
Which Features are Learnt by Contrastive Learning? On the Role of Simplicity Bias in Class Collapse and Feature Suppression
Generative Graph Dictionary Learning
Conformal Inference is (almost) Free for Neural Networks Trained with Early Stopping
Random Teachers are Good Teachers
Answering Complex Logical Queries on Knowledge Graphs via Query Computation Tree Optimization
RankMe: Assessing the Downstream Performance of Pretrained Self-Supervised Representations by Their Rank
Shapley Based Residual Decomposition for Instance Analysis
Building Neural Networks on Matrix Manifolds: A Gyrovector Space Approach