SetFit: Fine-tuning a LLM in 10 lines of code and little labeled data
SetFit: Fine-tuning a LLM in 10 lines of code and little labeled data
This blog is a follow-up to the series of posts
- Snorkel Credit Sentiment - Part 1 (May 2019)
- May the Fourth: VADER for Credit Sentiment? (May 2019)
- Experimenting with LIME - A tool for model-agnostic explanations of Machine Learning models (May 2019)
- Using LIME to ‘explain’ Snorkel Labeler (August 2019)
which share a common dataset of portfolio managers’ comments focused on the CDS market.
In this blog post, we illustrate how one can use a Large Language Model (LLM) and fine-tune it in just 10 lines of code (so easy nowadays) and only a small amount of labeled data (efficient few-short learning)!
We will use the Hugging Face Transformers library, and the recent SetFit framework:
SetFit is based on SBERT (Sentence-Transformers), and requires such a model as starting point. You can find pretrained models on the Hub.
Thanks to Alexis Marchal for pointing out this new framework to me!
The code content of this blog post can be found on this Google Colab.
Let’s now start our experiments to see if we manage to fine-tune a generalist LLM so that it “understands” Credit Default Swaps (CDS) using the SetFit framework.
We download a model to split text into sentences, as well as the necessary for Hugging Face Transformers and SetFit:
!python3 -m spacy download en_core_web_lg
!pip install torch
!pip install transformers datasets
!pip install setfit
We download the market comments:
!wget https://sp500-histo.s3.ap-southeast-1.amazonaws.com/blogs
We import relatively standard libraries:
import pickle
import pandas as pd
import spacy
from tqdm import tqdm
from pprint import pprint
We read the blogs. There are 1238 market comments available.
with open('blogs', 'rb') as f:
blogs = pickle.load(f)
len(blogs)
1238
Let’s look at one:
blogs[0]
{'title': 'That Is A Big Deal',
'author': 'jbchevrel',
'date': '2019-04-12',
'link': 'https://www.datagrapple.com/Blog/Show/12272/that-is-a-big-deal.html',
'content': 'In a decently risk-on session (CDX IG -2.8 CDX HY -8.9 SPX @ 2,900), the CDS of Anadarko Petroleum Corp. (APC) outperformed the broader market, tightening by c65bp. Bonds are also 75-100bp tighter. That is because the oil giant Chevron Corp. (CVX) agreed to buy APC. The equity is valued $33B, which will be paid in stocks and cash (75/25: 0.3869 CVX shares and $16.25 in cash per APC share). That is a 39% premium therefore APC share soared towards the offer price (+23% on day). The transaction is expected to close in 2H19. CVX management doesn’t expect any regulatory issues. From a credit standpoint, CVX will assume $15B net debt from APC, making APC EV c$50B. CVX will issue 200M shares and pay $8B in cash. A very tight name, CVX widened 6bp to 33bp mid, making the APC/CVX spread tighten 71bp, from +70bp to -1bp! CVX is not really a story for credit. Indeed, CVX has c$9.4B cash on hand and past experience proves that it generates $8B+ FCF per year at $50-55/bbl crude (vs now WTI $64), so it looks unlikely that they will fund the non-share cash part (c$8B) with debt. And even in the unlikely event it would do that, the combined leverage would be somewhere around 1x. Adding to this point, the news that 1/ CVX expects to realize $2B synergies (proceeds partly used for debt reduction) 2/ CVX plans to sell $15-20bn of assets in 2020-2022 confirms that CVX credit is not in trouble anytime soon. Therefore the consensus expects CVX to keep its current rating (AA/Aa2), while APC will converge to CVX from its Ba1/BBB, although we don’t know if CVX will explicitly guarantee them. CVX aside, this news dragged all the US/Canada IG energy tighter, with Hess -22 Devon -15 Encana -13, partly because the market knew APC was a target and consolidation was expected. This acquisition shows the importance of size in this business, where the biggest and the most diversified players do well. '}
We illustrate how we can use spacy to split the text into sentences:
nlp = spacy.load('en_core_web_lg')
text = blogs[0]['content']
doc = nlp(text)
for sent in doc.sents:
print(sent.text)
print()
In a decently risk-on session (CDX IG -2.8 CDX HY -8.9 SPX @ 2,900), the CDS of Anadarko Petroleum Corp. (APC) outperformed the broader market, tightening by c65bp.
Bonds are also 75-100bp tighter.
That is because the oil giant Chevron Corp. (CVX) agreed to buy APC.
The equity is valued $33B, which will be paid in stocks and cash (75/25: 0.3869 CVX shares and $16.25 in cash per APC share).
That is a 39% premium therefore APC share soared towards the offer price (+23% on day).
The transaction is expected to close in 2H19.
CVX management doesn’t expect any regulatory issues.
From a credit standpoint, CVX will assume $15B net debt from APC, making APC EV c$50B.
CVX will issue 200M shares and pay $8B in cash.
A very tight name, CVX widened 6bp to 33bp mid, making the APC/CVX spread tighten 71bp, from +70bp to -1bp!
CVX is not really a story for credit.
Indeed, CVX has c$9.4B cash on hand and past experience proves that it generates $8B+ FCF per year at $50-55/bbl crude
(vs now WTI $64), so it looks unlikely that they will fund the non-share cash part (c$8B) with debt.
And even in the unlikely event it would do that, the combined leverage would be somewhere around 1x.
Adding to this point, the news that 1/ CVX expects to realize $2B synergies (proceeds partly used for debt reduction) 2/ CVX plans to sell $15-20bn of assets in 2020-2022 confirms that CVX credit is not in trouble anytime soon.
Therefore the consensus expects CVX to keep its current rating (AA/Aa2), while APC will converge to CVX from its Ba1/BBB, although we don’t know if CVX will explicitly guarantee them.
CVX aside, this news dragged all the US/Canada IG energy tighter, with Hess -22
Devon -15
Encana -13, partly because the market knew APC was a target and consolidation was expected.
This acquisition shows the importance of size in this business, where the biggest and the most diversified players do well.
Not perfect, but good enough.
We apply the sentence splitting on the whole corpus, and end up with 9912 sentences:
all_sentences = []
for blog in tqdm(blogs):
text = blog['content']
doc = nlp(text)
for sent in doc.sents:
all_sentences.append(sent.text)
100%|██████████| 1238/1238 [01:12<00:00, 17.13it/s]
len(all_sentences)
9912
The last sentence of the corpus:
all_sentences[-1]
'The trading activity is 50% more important in Europe than in the US, with a 6BUSD per day for the iTraxx Europe members and 4BUSD per day for the CDX NA members (bubble colour) while the outstanding notional is 2.3TUSD and 1.7TUSD respectively (bubble size).'
Let’s focus in this blog on the “sentence sentiment analysis” task.
We can do that with readily available LLMs from the Hugging Face Hub:
from transformers import pipeline
sentiment_pipeline = pipeline("sentiment-analysis")
pprint(
sentiment_pipeline(
['The Abu Dhabi Machine Learning is soooo interesting!',
'I enjoy learning.',
'This talk is too long, but the networking event is worth it.',
'After this event, I will have to do the chores.'])
)
[{'label': 'POSITIVE', 'score': 0.9988824725151062},
{'label': 'POSITIVE', 'score': 0.9998513460159302},
{'label': 'POSITIVE', 'score': 0.9997938275337219},
{'label': 'NEGATIVE', 'score': 0.981780469417572}]
This works well off the shelf, as far as plain language is concerned.
Let’s apply it on the first four sentences of our corpus:
nb_sents = 4
results = sentiment_pipeline(all_sentences[:nb_sents])
for idx, sent in enumerate(all_sentences[:nb_sents]):
print(results[idx])
print(sent)
print()
{'label': 'NEGATIVE', 'score': 0.6894741058349609}
In a decently risk-on session (CDX IG -2.8 CDX HY -8.9 SPX @ 2,900), the CDS of Anadarko Petroleum Corp. (APC) outperformed the broader market, tightening by c65bp.
{'label': 'POSITIVE', 'score': 0.7168892621994019}
Bonds are also 75-100bp tighter.
{'label': 'NEGATIVE', 'score': 0.9830402731895447}
That is because the oil giant Chevron Corp. (CVX) agreed to buy APC.
{'label': 'NEGATIVE', 'score': 0.9756021499633789}
The equity is valued $33B, which will be paid in stocks and cash (75/25: 0.3869 CVX shares and $16.25 in cash per APC share).
The model is wrong: The first one is clearly positive from a credit market perspective. Sentence 3 and 4 are neutral, not negative.
Let’s now try with a LLM which has been trained for Financial Sentiment Analysis:
# https://huggingface.co/ahmedrachid/FinancialBERT-Sentiment-Analysis
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import pipeline
model = BertForSequenceClassification.from_pretrained(
"ahmedrachid/FinancialBERT-Sentiment-Analysis",
num_labels=3)
tokenizer = BertTokenizer.from_pretrained("ahmedrachid/FinancialBERT-Sentiment-Analysis")
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
Results are better:
nb_sents = 4
results = nlp(all_sentences[:nb_sents])
for idx, sent in enumerate(all_sentences[:nb_sents]):
print(results[idx])
print(sent)
print()
{'label': 'positive', 'score': 0.9998295307159424}
In a decently risk-on session (CDX IG -2.8 CDX HY -8.9 SPX @ 2,900), the CDS of Anadarko Petroleum Corp. (APC) outperformed the broader market, tightening by c65bp.
{'label': 'neutral', 'score': 0.9996776580810547}
Bonds are also 75-100bp tighter.
{'label': 'neutral', 'score': 0.9996036887168884}
That is because the oil giant Chevron Corp. (CVX) agreed to buy APC.
{'label': 'neutral', 'score': 0.9993715882301331}
The equity is valued $33B, which will be paid in stocks and cash (75/25: 0.3869 CVX shares and $16.25 in cash per APC share).
But the model gets it wrong on sentence 2. It is confident that the sentence is neutral whereas it is clearly positive (strong positive returns for bonds). The model was likely trained for general corporate news and fundamental releases with Equities (rather than Credit) in mind:
The model was fine-tuned for Sentiment Analysis task on Financial PhraseBank dataset. FinancialBERT model was fine-tuned on Financial PhraseBank, a dataset consisting of 4840 Financial News categorised by sentiment (negative, neutral, positive).
And, for the fun, let’s try another one: FinBERT Tone, a model proposed by Yi Yang (HKUST) who was a speaker at the Hong Kong Machine Learning meetup!
It is trained on the following three financial communication corpus. The total corpora size is 4.9B tokens. Corporate Reports 10-K & 10-Q: 2.5B tokens Earnings Call Transcripts: 1.3B tokens Analyst Reports: 1.1B tokens
# https://huggingface.co/yiyanghkust/finbert-tone
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import pipeline
finbert = BertForSequenceClassification.from_pretrained('yiyanghkust/finbert-tone', num_labels=3)
tokenizer = BertTokenizer.from_pretrained('yiyanghkust/finbert-tone')
nlp = pipeline("sentiment-analysis", model=finbert, tokenizer=tokenizer)
We face the same problem as with the previous model: It does not “understand” credit, and gets sentence 2 wrong.
nb_sents = 4
results = nlp(all_sentences[:nb_sents])
for idx, sent in enumerate(all_sentences[:nb_sents]):
print(results[idx])
print(sent)
print()
{'label': 'Positive', 'score': 0.9999912977218628}
In a decently risk-on session (CDX IG -2.8 CDX HY -8.9 SPX @ 2,900), the CDS of Anadarko Petroleum Corp. (APC) outperformed the broader market, tightening by c65bp.
{'label': 'Neutral', 'score': 0.9888407588005066}
Bonds are also 75-100bp tighter.
{'label': 'Neutral', 'score': 0.9999377727508545}
That is because the oil giant Chevron Corp. (CVX) agreed to buy APC.
{'label': 'Neutral', 'score': 1.0}
The equity is valued $33B, which will be paid in stocks and cash (75/25: 0.3869 CVX shares and $16.25 in cash per APC share).
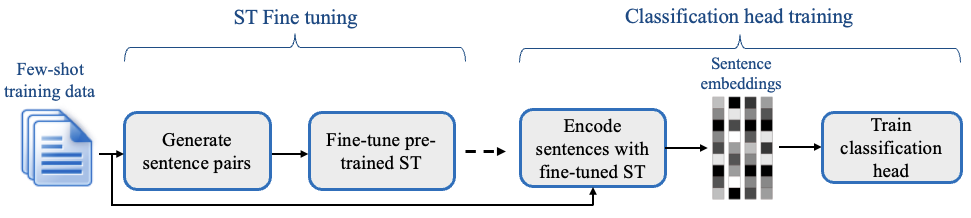
We now turn toward fine-tuning with the SetFit framework.
First, we have to start by defining a ‘training’ dataset:
import datasets
from datasets import Dataset
train_df = pd.DataFrame([
[all_sentences[500], 1],
[all_sentences[501], 1],
[all_sentences[601], -1],
[all_sentences[602], -1],
[all_sentences[702], -1],
[all_sentences[703], 0],
[all_sentences[704], 0],
[all_sentences[706], 0],
[all_sentences[707], -1],
[all_sentences[708], -1],
[all_sentences[709], -1],
[all_sentences[711], 0],
[all_sentences[755], 0],
[all_sentences[857], 0],
[all_sentences[957], 0],
[all_sentences[1005], 0],
[all_sentences[1205], 1],
[all_sentences[1213], 0],
["the spread widened recently", -1],
["bonds were 80bps wider at the close", -1],
["cds spreads increased by 20 bps over the week", -1],
["single names traded wider across the board", -1],
["credit indices opened 1bp wider today", -1],
["bond prices were down by a few points", -1],
["prices plunged after the open", -1],
["credit spreads have increased year to date", -1],
["the cds of this company tightened since the start of the week", 1],
["credit spreads are now tighter than at the start of the month", 1],
["bond prices were up today", 1],
["the cds traded at its tightest", 1],
["credit rallied since the open", 1],
["cds spreads decreased overnight", 1],
["risk-on session for credit", 1],
["credit spreads are very low", 1],
])
train_df.columns = ['text', 'label']
train_dataset = Dataset.from_pandas(train_df)
print(train_dataset)
Dataset({
features: ['text', 'label'],
num_rows: 34
})
train_dataset.to_pandas()
| text | label | |
|---|---|---|
| 0 | This rare piece of good news allowed TCGLN’s 5... | 1 |
| 1 | That is 136bps tighter than the recent wides r... | 1 |
| 2 | There are also question marks regarding the st... | -1 |
| 3 | Its proposal to legally separate the network f... | -1 |
| 4 | It repriced the whole complex and sent INTNEDG... | -1 |
| 5 | But when there is no substance behind that new... | 0 |
| 6 | Over the last few sessions, arbitrageurs have ... | 0 |
| 7 | No change on balance sheet normalisation was m... | 0 |
| 8 | Credit widening gathered momentum as NY came i... | -1 |
| 9 | Along with other risky assets, crude oil fell ... | -1 |
| 10 | MO (+30) widened the most. | -1 |
| 11 | The main cause here seems to be the $12.8B inv... | 0 |
| 12 | 2/ some early news of the sale of the ServiceM... | 0 |
| 13 | 2/ The EC informally recommended a debt-based ... | 0 |
| 14 | This is after BOPRLN agreed to sell its Manton... | 0 |
| 15 | United Natural Foods is currently trying to lu... | 0 |
| 16 | The 5y CDS closed -55bp on the day, -80bp from... | 1 |
| 17 | But Markit published the lists of provisional ... | 0 |
| 18 | the spread widened recently | -1 |
| 19 | bonds were 80bps wider at the close | -1 |
| 20 | cds spreads increased by 20 bps over the week | -1 |
| 21 | single names traded wider across the board | -1 |
| 22 | credit indices opened 1bp wider today | -1 |
| 23 | bond prices were down by a few points | -1 |
| 24 | prices plunged after the open | -1 |
| 25 | credit spreads have increased year to date | -1 |
| 26 | the cds of this company tightened since the st... | 1 |
| 27 | credit spreads are now tighter than at the sta... | 1 |
| 28 | bond prices were up today | 1 |
| 29 | the cds traded at its tightest | 1 |
| 30 | credit rallied since the open | 1 |
| 31 | cds spreads decreased overnight | 1 |
| 32 | risk-on session for credit | 1 |
| 33 | credit spreads are very low | 1 |
We import a pretrained Sentence-Transformers model, here “sentence-transformers/paraphrase-mpnet-base-v2”.
The embeddings of such models have been built such that they are useful for semantic textual similarity whereas standard BERT embeddings are not very good at this task by default.
from setfit import SetFitModel
model = SetFitModel.from_pretrained(
"sentence-transformers/paraphrase-mpnet-base-v2")
SetFit leverages this model, and trains a classification head based on a small number of labeled examples only:
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitTrainer
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=None,
loss_class=CosineSimilarityLoss,
num_iterations=20,
)
trainer.train()
The model obtained is now correct on the validation sentences:
preds = model(all_sentences[:nb_sents])
probas = model.predict_proba(all_sentences[:nb_sents])
for idx, sent in enumerate(all_sentences[:nb_sents]):
print(preds[idx])
print(probas[idx, :].numpy())
print(sent)
print()
tensor(1)
[0.04064713 0.02571009 0.93364278]
In a decently risk-on session (CDX IG -2.8 CDX HY -8.9 SPX @ 2,900), the CDS of Anadarko Petroleum Corp. (APC) outperformed the broader market, tightening by c65bp.
tensor(1)
[0.01136821 0.01758817 0.97104362]
Bonds are also 75-100bp tighter.
tensor(0)
[0.12991872 0.80673081 0.06335047]
That is because the oil giant Chevron Corp. (CVX) agreed to buy APC.
tensor(0)
[0.22094609 0.70386868 0.07518523]
The equity is valued $33B, which will be paid in stocks and cash (75/25: 0.3869 CVX shares and $16.25 in cash per APC share).
And, we can check that it gets the credit spreads meaning right:
preds = model(
["credit spreads increased",
"credit spreads decreased",
"cds tightened across the board",
"cds spreads widened",
"Elon Musk bought Twitter",
"The company will release earnings next week"])
preds
tensor([-1, 1, 1, -1, 0, 0])
pd.DataFrame(
trainer.model.predict_proba(
["credit spreads increased",
"credit spreads decreased",
"cds tightened across the board",
"cds spreads widened",
"Elon Musk bought Twitter",
"The company will release earnings next week"]
).numpy(),
columns=['negative', 'neutral', 'positive']
)
| negative | neutral | positive | |
|---|---|---|---|
| 0 | 0.951350 | 0.009351 | 0.039298 |
| 1 | 0.025996 | 0.017229 | 0.956775 |
| 2 | 0.042988 | 0.012111 | 0.944900 |
| 3 | 0.953140 | 0.008496 | 0.038364 |
| 4 | 0.358724 | 0.531684 | 0.109592 |
| 5 | 0.124232 | 0.757476 | 0.118292 |
Conclusion: SetFit is a very promising approach for fine-tuning large language models to particular use cases and jargon.