Snorkel Credit Sentiment - Part 1
First experiment with Snorkel Metal – Credit Sentiment on DataGrapple blogs
Snorkel is a system for labelling data, at scale. In order to use advanced and complex machine learning models (say, deep learning models), one needs data, a lot of data.
Most of the time, outside academia or big tech b2c companies, one virtually starts with 0 labelled data for a given problem.
How to quickly bootstrap a large labelled dataset? Many tricks are available to the astute practitioner. Imho, this skillset is the real value, neither importing keras, nor reading 50 ICML/NeurIPS/ACL papers a day.
Besides pre-training/transfer learning for NLP (ELMo, ULMFiT, BERT, GPT-2 which give good representation to start with - learning representations from scratch on too small corpuses leads to underperformance, either overfitting or barely fitting at all), the Snorkel approach, an example of the paradigm of data programming, is here to help combine several weak labelers into a final strong one. Each of these weak labelers have their own different coverages, biases and variances, and they are correlated each other to some extent. Snorkel leverages their statistics to combine them in a smart way. For technical details, cf. the paper. For financial minded people, think “benefit of diversification”.
In practice, in the case of a sentiment NLP task in finance, these weak labelers can be
- humans,
- string lookup from a polarized dictionary,
- regular expressions,
- pre-trained classifiers,
- meta-data,
- future performance of assets,
- …
To start experimenting with the Snorkel framework, we will use only polarized expressions (good for asset future performance vs. bad for asset future performance) that are searched for in the text.
import re
import pickle
import numpy as np
import pandas as pd
from scipy import sparse
from sklearn.metrics import confusion_matrix, f1_score
from metal.label_model import LabelModel
from metal.analysis import lf_summary, label_coverage
from metal.label_model.baselines import MajorityLabelVoter
DataGrapple blogs
For this experiment, we will use credit focused blogs published daily by Hellebore Capital portfolio managers. These blogs can be found there on the DataGrapple platform.
with open('./blogs', 'rb') as file:
blogs = pickle.load(file)
print("We consider for the in-sample", len(blogs), "blogs.")
We consider for the in-sample 1238 blogs.
We reformat the blogs by appending title and body, and stripping new lines and tabs.
blogs = pd.DataFrame([blog['title'].replace('\t', '')
+ ' ' + blog['content'].replace('\t', '').replace('\n', '').replace('\r', '')
for blog in blogs],
index = [i for i in range(len(blogs))])
blogs.head()
| 0 | |
|---|---|
| 0 | That Is A Big Deal In a decently risk-on sessi... |
| 1 | Only Game In Town Today, the ECB pretty much d... |
| 2 | Impairment Bites HEMA (short for 4 unpronounce... |
| 3 | On The Red Today the 5y CDS of Crown Resorts L... |
| 4 | Shipping Names Rocked Today CMA CGM (CMACG) an... |
Weak labelers
For now, we will consider only weak labelers that are polarized expressions according to credit. Notice that the polarization (negative or positive) can be different if one considers different asset classes. For example, a good news for creditors (say cut of dividends) can be a bad news for shareholders.
We design the following weak labelers as an attempt to capture the following factors:
- performance (of the asset or the business),
- quality / ratings,
- general market/investor sentiment,
- frauds,
- defaults.
Each labeling function gets as input the content of the blog, looks up if a string corresponding to its polarized factor is included in the content, if yes than returns the polarization, otherwise it abstains from labeling.
ABSTAIN = 0
POSITIVE = 1
NEGATIVE = 2
PERFORMING = r"""\b(\d+bps tighter|tighter by \d+bp|credit spreads tighten across the board|back to the lowest spread level|CDS tightens back|little appetite to bid for single-name protection|stock up|strong performance|spreads tightening|performed|tighter|tighten|beating expectations|best performers|best performing|outperformance|outperforming|outperformer|outperformers)"""
def contains_performing_expressions(text):
return POSITIVE if re.search(PERFORMING, text) else ABSTAIN
GOOD_RATINGS = r"\b(S&P upgraded|upgrade|upgraded|upgraded by Fitch|upgraded by Moody's)"
def contains_upgrade_expressions(text):
return POSITIVE if re.search(GOOD_RATINGS, text) else ABSTAIN
GOOD_MOODS = r"\b(reassured credit investors|good short-term option|risk-on|positively in credit|dovish|guidance was positive|good for credit|issues have been pushed back|bullish)"
def contains_good_mood_expressions(text):
return POSITIVE if re.search(GOOD_MOODS, text) else ABSTAIN
GOOD_LIQUIDITY = r"\b(resolve the liquidity issue)"
def contains_good_liquidity_expressions(text):
return POSITIVE if re.search(GOOD_LIQUIDITY, text) else ABSTAIN
BAD_MOODS = r"\b(risk-off|tough test|disappointed|continued deterioration|challenging for credit|brutal punishment|hawkish|profit warning|dampen credit outlook|bearish)"
def contains_bad_mood_expressions(text):
return NEGATIVE if re.search(BAD_MOODS, text) else ABSTAIN
UNDERPERFORMING = r"""\b(cut its profit forecast|stocks fall|higher leverage|shares plunged|widened \d+bp|CDS widened c\d+bp|bonds fell roughly \d+pts|stock got crushed|quarterly profit miss|shares sunk|loses money|risk premium through the roof|stock lost|revenues declined|downtrend in revenue|Q[1-4] results missed|bonds were trashed|defaulted on its debt|survival of the company is under threat|lost its leadership|Q[1-4] sales missed|weaker demand|sales down|stocks declined|bid single-name protection|weakens credit metrics|profit warnings|guidance dropped|missed the estimates|worst-performing|widening|underperformers|widen +\d+bp|under more pressure|curve is inverted|worst performing|CDS is wider|underperforming|underperformed|bonds were down|CDS widen by c\d+bp)"""
def contains_underperforming_expressions(text):
return NEGATIVE if re.search(UNDERPERFORMING, text) else ABSTAIN
BAD_RATINGS = r"\b(Fitch downgraded|outlook to negative|downgrade|downgraded|outlook at negative)"
def contains_downgrade_expressions(text):
return NEGATIVE if re.search(BAD_RATINGS, text) else ABSTAIN
FRAUDS = r"\b(money laundering|scandal)"
def contains_fraud_expressions(text):
return NEGATIVE if re.search(FRAUDS, text) else ABSTAIN
DEFAULTS = r"\b(filed for bankruptcy|chapter 11|filed for creditor protection|continue as a going concern)"
def contains_default_expressions(text):
return NEGATIVE if re.search(DEFAULTS, text) else ABSTAIN
BAD_MOMENTUM = r"\b(risk premium has tripled)"
def contains_bad_momentum_expressions(text):
return NEGATIVE if re.search(BAD_MOMENTUM, text) else ABSTAIN
CATASTROPHE = r"\b(devastating impact|struck by hurricane)"
def contains_catastrophe_expressions(text):
return NEGATIVE if re.search(CATASTROPHE, text) else ABSTAIN
LFs = [
contains_performing_expressions,
contains_upgrade_expressions,
contains_good_mood_expressions,
contains_good_liquidity_expressions,
contains_underperforming_expressions,
contains_downgrade_expressions,
contains_bad_mood_expressions,
contains_fraud_expressions,
contains_default_expressions,
contains_bad_momentum_expressions,
contains_catastrophe_expressions,
]
LF_names = [
'performing',
'upgrade',
'good_mood',
'good_liquidity',
'underperforming',
'downgrade',
'bad_mood',
'fraud',
'default',
'bad_momentum',
'catastrophe',
]
Evaluation of the weak labelers
Next step is to evaluate each weak labeler in terms of coverage, accuracy, contradictions and overlaps with the other weak labelers.
Ideally, we want to reach high global coverage as this set of weak labelers will be used to label the whole corpus we have for training.
def make_Ls_matrix(data, LFs):
noisy_labels = np.empty((len(data), len(LFs)))
for i, row in data.iterrows():
for j, lf in enumerate(LFs):
noisy_labels[i][j] = lf(row.values[0].lower())
return noisy_labels
Below I load the “true” labels I did by reading 130 blogs in order to have
- an evaluation set for the weak labelers,
- a training set for the combination of these weak labelers into a strong labeler.
N.B. This strong labeler is not the final classifier model, it is just an intermediate step to have cleaner labels on all the texts of the corpus.
# Get true labels for LF set
with open('labels_for_training_labelling', 'rb') as file:
labels = pickle.load(file)
print('Number of manually labeled examples:', len(labels),
'\nRatio of blogs labeled:', round(len(labels) / len(blogs), 2),
'\nRatio positive:', round(len([val for key, val in labels.items() if val == 1]) / len(labels), 2))
Number of manually labeled examples: 130
Ratio of blogs labeled: 0.11
Ratio positive: 0.42
# We build a matrix of LF votes for each DG blog
LF_matrix = make_Ls_matrix(blogs.iloc[:len(labels)], LFs)
Y_LF_set = np.array([labels[i] for i in range(len(labels))])
lf_summary(sparse.csr_matrix(LF_matrix),
Y=Y_LF_set,
lf_names=LF_names)
| j | Polarity | Coverage | Overlaps | Conflicts | Correct | Incorrect | Emp. Acc. | |
|---|---|---|---|---|---|---|---|---|
| performing | 0 | 1.0 | 0.492308 | 0.230769 | 0.161538 | 43 | 21 | 0.671875 |
| upgrade | 1 | 1.0 | 0.023077 | 0.015385 | 0.000000 | 3 | 0 | 1.000000 |
| good_mood | 2 | 1.0 | 0.146154 | 0.146154 | 0.076923 | 15 | 4 | 0.789474 |
| good_liquidity | 3 | 1.0 | 0.007692 | 0.007692 | 0.000000 | 1 | 0 | 1.000000 |
| underperforming | 4 | 2.0 | 0.353846 | 0.238462 | 0.130769 | 36 | 10 | 0.782609 |
| downgrade | 5 | 2.0 | 0.076923 | 0.053846 | 0.015385 | 10 | 0 | 1.000000 |
| bad_mood | 6 | 2.0 | 0.130769 | 0.130769 | 0.046154 | 14 | 3 | 0.823529 |
| fraud | 7 | 2.0 | 0.030769 | 0.023077 | 0.023077 | 4 | 0 | 1.000000 |
| default | 8 | 2.0 | 0.023077 | 0.000000 | 0.000000 | 3 | 0 | 1.000000 |
| bad_momentum | 9 | 2.0 | 0.007692 | 0.007692 | 0.007692 | 1 | 0 | 1.000000 |
| catastrophe | 10 | 2.0 | 0.007692 | 0.007692 | 0.000000 | 1 | 0 | 1.000000 |
We can observe that the downgrade/upgrade by ratings agencies have a perfect accuracy but also very low coverage. Same for fraud related news. “Performing” and “underperforming” expressions have the highest coverage, but also the least accuracy. Indeed, several blogs mention several asset classes: conventions are different (an increase in stock price vs. an increase in credit spread) and expressions may trigger on sentences unrelated to credit; interests are not the same across the capital structure (a large bond issuance is usually bad news for existing bond holders, but can be good news for shareholders as proceeds can be used to finance expansion projects). The latter labeling functions have also the highest conflicts with other labeling functions.
LF_matrix = make_Ls_matrix(blogs.iloc[:len(labels)], LFs)
print("Overall, we reach a coverage ratio of", round(label_coverage(LF_matrix), 2), "over the training subset.")
LF_matrix = make_Ls_matrix(blogs, LFs)
print("Overall, we reach a coverage ratio of", round(label_coverage(LF_matrix), 2), "over the whole training set.")
Overall, we reach a coverage ratio of 0.82 over the training subset.
Overall, we reach a coverage ratio of 0.66 over the whole training set.
Comparison of a naive combination (majority vote) vs. Snorkel combination
Baseline: majority vote
mv = MajorityLabelVoter()
Ls_train = make_Ls_matrix(blogs.iloc[:len(labels)], LFs)
mv = MajorityLabelVoter(seed=42)
print("Basic majority vote labels performance:")
scores = mv.score((Ls_train, Y_LF_set), metric=['accuracy','precision', 'recall', 'f1'])
Basic majority vote labels performance:
Accuracy: 0.769
Precision: 0.671
Recall: 0.870
F1: 0.758
y=1 y=2
l=1 47 23
l=2 7 53
Training and evaluation of Snorkel strong labeler
Ls_train = make_Ls_matrix(blogs, LFs)
label_model = LabelModel(k=2, seed=42)
label_model.train_model(Ls_train,
Y_dev=Y_LF_set,
n_epochs=1000,
lr=0.01,
log_train_every=2000)
Computing O...
Estimating \mu...
Finished Training
Ls_train = make_Ls_matrix(blogs.iloc[:len(labels)], LFs)
print("Snorkel generated labels performance:")
scores = label_model.score((Ls_train, Y_LF_set), metric=['accuracy','precision', 'recall', 'f1'])
Snorkel generated labels performance:
Accuracy: 0.792
Precision: 0.800
Recall: 0.667
F1: 0.727
y=1 y=2
l=1 36 9
l=2 18 67
We obtain a labeler with higher precision, lower recall on the train/dev set.
Ls_train = make_Ls_matrix(blogs, LFs)
Y_train_ps = label_model.predict_proba(Ls_train)
Y_train_ps
array([[0.32981018, 0.67018982],
[0.58778564, 0.41221436],
[0.1969271 , 0.8030729 ],
...,
[0.17259519, 0.82740481],
[0.58778564, 0.41221436],
[0.58778564, 0.41221436]])
from metal.contrib.visualization.analysis import (
plot_predictions_histogram,
plot_probabilities_histogram,
)
plot_predictions_histogram(Y_LF_set,
label_model.predict(Ls_train[:len(labels)]),
title="Label Distribution")
Y_dev_ps = label_model.predict_proba(Ls_train[:len(labels)])
plot_probabilities_histogram(Y_dev_ps[:, 0],
title="Probablistic Label Distribution for POSITIVE")
plot_probabilities_histogram(Y_dev_ps[:, 1],
title="Probablistic Label Distribution for NEGATIVE")
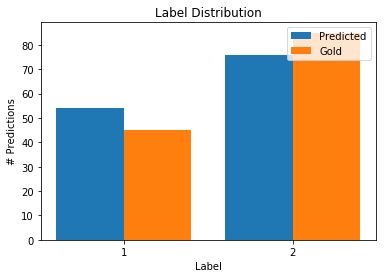
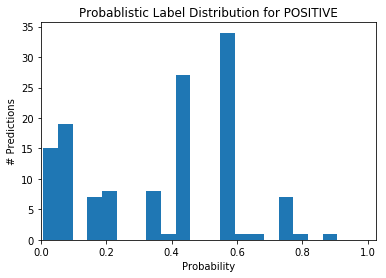
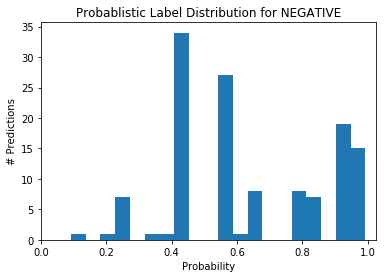
We can notice that the labeler struggles to label the blogs. If it were sure of its labels, we would observe most of the predictions with either a probability near 0 or near 1.
Let’s check a few examples at random:
print(blogs.iloc[500][0], "\n\n", Y_train_ps[500])
In Mario We Trust It was a strong day right from the start, extending the trend that emerged after the Italian referendum. Since the wides reached early on Monday, iTraxx Main (ITXEB) has tightened by 8bps (it closed at 74bps tonight), iTraxx Crossover (ITXEX) by 25bps (it closed at 315.5bps tonight which is the series tights) and iTraxx Financial Senior by 13bps (it closed at 99.5bps tonight). One would have expected the move to happen after the ECB meeting which is taking place tomorrow. But even if market participants see it as the last chance for some volatility in 2016, it looks as though right now they are pricing a very benign outcome. It is also fairly obvious from the option market where implied volatility came down aggressively over the last few days. For ITXEB, options are pricing a total move of less than 5bps until the December expiry (which takes place in 2-week time), going into an important ECB meeting – during which investors expect to get some clues regarding the direction of the purchase program in 2017 - while previous ones have been the drivers of the biggest moves in credit so far this year.
[0.58778564 0.41221436]
print(blogs.iloc[700][0], "\n\n", Y_train_ps[700])
Well Behaved Today was the 4th session in a row of credit indices tightening. Europe has led the charge, driven by financials which are now well of their widest levels. iTraxx Financials Senior (ITXES), which was trading at 140bps as recently as last Thursday, closed tonight at 113bps. With iTraxx Main (ITXEB) and CDXIG closing tonight at 108bps and 117bps respectively, it is as if the few sessions where they traded on top of each other never happened. ITXEB is coming back to 100bps as fast as it went out to 127bps. Less than 2 weeks were necessary to cover these 50bps. But the most striking is how well behaved the market has been during this burst of volatility. Credit indices and single reference CDS have move in unison. Today for instance, the basis of ITXEB (the difference of the quoted value of the index and the theoretical value computed with the risk premia of its constituents) moved by less than 2cts during an index move of almost 30cts. The basis of ITXES moved by less than 4cts for an index move in excess of 35cts.
[0.58778564 0.41221436]
print(blogs.iloc[1100][0], "\n\n", Y_train_ps[1100])
Basis Dynamics Through The Roll Single names CDS rolled on the 20th June as they do each quarter, and the most liquid maturities have been pushed by a quarter. For instance, the “on-the-run” 5 year maturity is now September 2019 while it was June 2019 a week ago. Credit indices on their side only roll twice a year, and the “on-the-run” 5 year investment grade index is still iTraxx Main S21 with a June 2019 maturity. On indices, on the 20th June, dealers just took things where they left it the day before and resume trading as if nothing had happened. On single names, dealers should have factored in their prices the maturity extension. But there is always a tendency to leave their 5 year quotes unchanged, or at least a tendency not to reflect fully the increase in risk premium coming from the 3 months added to the maturity of new on the run contracts. This is particularly true in a bullish environment, like the one which prevails at the moment. This grapple shows that this naturally led to an increase in the basis between credit indices and their theoretical values.
[0.62634118 0.37365882]
The three comments above are correctly labeled as positive for credit.
print(blogs.iloc[600][0], "\n\n", Y_train_ps[600])
Is Brexit Good For Some? Japan woke up this morning to the tune of M&A; after a three-day-week-end. Japanese telecom group SOFTBK ( SoftBank Group Corp ) is offering a 43% premium to Friday’s close to acquire ARM Holdings Plc , a UK mobile industry leader, for £24.3Bln. The bumper deal would be one of the largest European technology transactions and Softbank’s largest acquisition to date. ARM derives the vast majority of its revenues from Asia and North America with clients such as Apple, Samsung Electronics or Qualcomm, and should be relatively immune from Brexit. So the main impact of the coming UK’s exit from the EU at the moment is the roughly 12% fall of the British Pound against the Japanese Yen. It certainly makes the deal more attractive, but given the steady rise of ARM’s stock since the beginning of May and the hefty premium paid, the operation still means that SOFTBNK’s net debt to EBITDA could rise from 3.9 times to 4.6 times. No wonder investors pushed SOFTBNK’s 5 year risk premium 35bps wider to 155bps.
[0.41538462 0.58461538]
This one was correctly labeled as negative for (SOFTBNK) credit.
Let’s have a look at the top 5 most confident (blog, label) for each category:
print("POSITIVE for credit:", "\n")
pos_sorted_idx = np.argsort(Y_train_ps[:, 0])
print(pos_sorted_idx[-5:], "\n")
for i in range(5):
idx = pos_sorted_idx[-i-1]
print(blogs.iloc[idx][0], "\n")
print(Y_train_ps[idx])
print('-' * 115)
POSITIVE for credit:
[ 9 515 1005 565 69]
Falling Knife Catching: The -16% rule General Electric Company (GE) was the big mover (again) today. The 5y CDS is 23bp tighter, making the name the best performer in the CDX IG, and by far (other single names are -6/+6). Cash is also c25bp tighter and the stock was is +7%, as I write. This rather bullish move comes mainly after 2 developments: 1/ the upgrade by the J.P. Morgan analyst.2/ some early news of the sale of the ServiceMax stake. On the former, it is worth noting that the J.P. Morgan analyst now has for GE a price target of $6. Implying a drop from here of... -16%. A quick look in the rear-view mirror shows that since Nov 12, GE 5y CDS is unchanged. Over the same period, GE stock is... -16%. Elsewhere it was a rather firm day with CDS indices slightly tighter (Main -1 CDX IG -1). Noteworthy that volumes and liquidity were low, as we approach the end of the year.
[0.90775322 0.09224678]
-------------------------------------------------------------------------------------------------------------------
Investment Grade Status Matters Bond issuance is on course to break record since the end of the holiday season, and today saw more corporates try and take advantage of record low borrowing costs. Among companies aiming to tap investors’ liquidity, Schaeffler AG marketed €2.5Bln so-called payment in kind debt - which give it the option to pay interest with more debt – that will have maturities of 5, 7, and 10 years. The deal will enable the company to refinance the existing debt of IHO, the holding company of the group, and intends to reduce the indebtedness at Schaeffler AG by roughly €700Bln. Moody’s swiftly upgraded the company to investment grade, and investors send SHAEFF’s (Schaeffler Finance B.V.) 5-year risk premium 30bps tighter to 105bps.The broader market experienced another strong session on balance, even if credit indices are closing off their tightest levels led by some weakness in the US. For now, iTraxx Main has still not broken the 65 level, on which it has bounced a few times since the beginning of August. A lot of hedges have come off recently ahead of tomorrow’s ECB meeting, and it looks as if the market is expecting something from Mr Draghi, which leaves room for disappointment.
[0.8066213 0.1933787]
-------------------------------------------------------------------------------------------------------------------
Rating Still Matters (Sometimes) The session turned out to be fairly strong across the board, and there were only a handful of names which closed wider on the day. The tone was a bit more hesitant in the morning though, as people feared that the bank holiday in the US tomorrow would weight on liquidity. In the early hours of trading, RENAUL ( Renault SA ) was one of the standout names. It started the day strongly on the back of an upgrade by Fitch. The rating agency revised RENAUL’s rating to BBB- outlook positive, bringing it back in the investment grade category. The 5 year CDS quickly tightened by 15bps (it closed at 112.5bps) as buyers of cash started to emerge. Indeed, if this upgrade took place earlier that investors had anticipated, they now expect S&P; and Moodys to follow suit. If that happens, investment grade funds will start to buy cash, which should lead to further outperformance. Rating actions still matter, especially for names that sit on the border of investment grade and high yield.
[0.8066213 0.1933787]
-------------------------------------------------------------------------------------------------------------------
It Was Not Trump On the 9th November HEIGR’s ( HeidelbergCement AG ) 5-year risk premium had one its best day of the last 6 months. On that day, the company reported its third quarter results and, despite a miss, reassured somewhat investors when it confirmed guidance for the full year. It was not the reason behind the tightening of its 5-year CDS though. Neither was it due to the shock results of the US elections which catapulted to power Mr Trump and his $500Bln construction goal. On that day, HEIGR was assigned an investment grade rating by S&P.; Investors did not spend too much time reading the rationale of the upgrade. They merely factored in the price of its debt the fact that going forward it would be eligible to the ECB Corporate Sector Purchase Program. The presence of that newfound buyer made all the difference.
[0.8066213 0.1933787]
-------------------------------------------------------------------------------------------------------------------
Reversion? Koninklijke KPN N. V. (KPN) was among best performers in iTraxx Main today, 5y CDS being tighter by 10bp, vs -2.7bp for the index and -1.8bp for the index fair value. It follows the -14bp move on Friday. This outperformance is due to beta, but not only. Indeed, on Friday, S&P; upgraded KPN to BBB Stable from BBB- following the agency’s view that KPN credit metrics should cross its thresholds for a mid BBB rating despite potential restructuring charges. As a result, KPN is now Baa3/BBB. Management’s commitment to achieve a mid-term leverage below 2.5x likely helped that decision. S&P; also commented on a potential bid from Brookfield Asset Management, which caused the CDS spread to soar (55->130) earlier this year. We tighten back today also as the probability of this deal looks to have decreased. Indeed, the agency said that such a development is sufficiently remote for now, for a few reasons. Firstly, it believes that KPN’s independent foundation would use its voting control to block any offer that could be dangerous for lenders. Secondly, it argues that the recently proposed legislation in the Netherlands could allow the government to intervene in such a takeover. That making the path to a deal more complex for Brookfield, we logically reverted tighter to 115 mid on the 5y, which is still top of the range, as the deal is still far from off the table.
[0.8066213 0.1933787]
-------------------------------------------------------------------------------------------------------------------
print("NEGATIVE for credit:", "\n")
neg_sorted_idx = np.argsort(Y_train_ps[:, 1])
print(neg_sorted_idx[-5:], "\n")
for i in range(5):
idx = neg_sorted_idx[-i-1]
print(blogs.iloc[idx][0], "\n")
print(Y_train_ps[idx])
print('-' * 115)
NEGATIVE for credit:
[696 36 327 477 47]
A Tax Break Is Not Enough The market was fairly confident going into the FOMC meeting, and risk enjoyed a positive session across the board. There were a few outliers and things did not pan out very well for PEMEX’s (Petroleos Mexicanos) credit investors. The company has seen oil output decline every year since 2004 and is Latin America’s most indebted borrower. It loses money on its inefficient refining business and because of endemic fuel theft – the company reports as many as 41 illegal pipeline taps every day -, which led to the tragedy that killed more than 100 people 10 days ago. Yesterday night Fitch downgraded Mexico’s oil producer to one notch above junk despite the government proposed $3.5Bln cut from its taxes. The downgrade to BBB- reflects the “continued deterioration of PEMEX’s standalone credit profile” and the “under-investment in the company’s upstream business” according to Fitch. They added that the company had been technically insolvent since 2009 by having a negative total equity balance. PEMEX’s 5-year risk premium jumped 29bps to 315bps, off the 270bps tights reached a couple of days ago.
[0.00724025 0.99275975]
-------------------------------------------------------------------------------------------------------------------
The (Not So Good) Italian Job BRITEL ( BT Group Plc ) delivered a double blow to investors. It revealed that the impact of an accounting scandal in its Italian business is nearly four times worse than originally thought. From £145mln, the write down has now ballooned to £530mln. As bad as the news was, it was not the worst though! The company also issued a profit warning for this year and next, as it has begun to factor in the impact of Brexit. While individual consumers are holding up well, the UK’s decision to leave the European Union is translating into weaker demand from public sector customers in the UK and big multinationals overseas. To maintain the dividend, tough decisions will have to be made given BRITEL’s upcoming obligations on pension payments and the prospect of more intense competition for its British consumer business, now that pay-TV leader Sky Plc is offering mobile services and Virgin Media is building more fibre lines. In light of these challenges, investors knocked the stock by almost 18% and pushed BRITEL’s 5-year risk premium 9bps wider, making it one of the only names wider in the European investment grade universe.Meanwhile, the broader credit market resumed normal service after a couple of days of weakness. All credit indices closed at tighter levels today, with iTraxx Subordinated leading the charge (-10bps at 202.5bps, which is the tightest level of the current series).
[0.01479096 0.98520904]
-------------------------------------------------------------------------------------------------------------------
Brick And Mortar Can Hurt Too CAFP ( CArrefour ) surprised the market today with a profit warning. Its shares plunged more than 13% and its 5-year risk premium increased 9bps to 64bps after the company said that full year operating profit will decline a similar amount as the 12% drop in the first half. Alexandre Bompard, CAFP’s new CEO, has been recruited partly for his ability to see off the likes of Amazon, after he gained a reputation for his digital expertise when he successfully steered Fnac Darty into e-commerce. While CAFP was hit by difficulties in Argentina, it mostly had to face a step-up in competition on its home turf, as Leclerc, the low-price supermarket chain, overtook CAFP as France’s biggest grocer by market share. Leclerc recently grew more aggressive in its promotions, and CAFP had to beef up its own price cuts, one of the main factors behind its warning that the second part of the year will be as tough as the first. If on-line retailers are certainly a threat, brick and mortar competitors can cause pain too.
[0.02008951 0.97991049]
-------------------------------------------------------------------------------------------------------------------
No WIN For Windstream When US High Yield investors left for a long week-end on Friday, they were certainly not expecting the brutal punishment that was inflicted on WIN ( Winstream ) during today’s session. The very survival of the company is under threat after the surprise ruling late last week by a Manhattan federal court that it defaulted on its debt by spinning off Uniti Group Inc in 2015. It contends that some of WIN’s bondholders were unfairly stripped of assets that backed up their investment. The judgement was made on the back of an action undertaken by Aurelius Capital Management, but the $310mln awarded to the fund could only be the beginning. Other creditors could claim cross defaults on other parts of WIN’s debt which totals roughly $5.8Bln. The ruling means that creditors could ask their trustees to file notices to accelerate their debt and seek immediate repayment. WIN’s bonds were trashed, and the company’s 5-year risk premium reached 70% upfront. That means you have to pay 70cts upfront to insure $1 of WIN’s debt against a default within 5 years, and an additional 5cts per year. The market now assesses that WIN has only 1 in five chances to make it through the next 12 months.
[0.02008951 0.97991049]
-------------------------------------------------------------------------------------------------------------------
The Weakest Link The last few days have gradually set the scene of a lower volatility environment as far as credit is concerned. This is slowly bringing confidence back to the market and we have seen a steady stream of protection selling across the board on credit indices over the last few days. Today credit indices significantly outperformed equities which were heading south in the afternoon while credit was barely moving. But the feel-good factor is not affecting all sectors indiscriminately, and Financials still appeared weak today. Yesterday HSBC’s (HSBC Holdings Plc) results disappointed investors, and today STANLN’s (Standard Chartered) did not fare any better and set the tone for banks, which underperformed the rest of the market. Even though Financials is still the most actively traded sector, liquidity felt challenging at times, and aggressive protection offers were few and far between.
[0.02008951 0.97991049]
-------------------------------------------------------------------------------------------------------------------
The snorkel labeler seems to do a pretty decent job.
This component is usually used to label at scale huge datasets before applying some supervised learning technique such as a deep learning classifier than can leverage better all this labeled data.
In this case, we have only less than 1300 blogs available. Not enough for training a proper NLP language model + classifier from scratch.
We will test in a future blog whether BERT and the likes can help us on this credit sentiment task, i.e. help us doing better than this seemingly strong baseline which consists in leveraging “expert” rules without much machine learning but for the use of the ‘diversification’ generative model that yields the probabilitic labels.
It is not totally clear to me that these pre-trained (on Wikipedia) language models can help us significantly for this specific task as market comments are heavy in jargon, conventions, and implicit information (sentiment can come from a deviation of the market expectation which is not clearly stated in the text).