[paper] Top2Vec: Distributed Representations of Topics
with application on 2020 10-K business descriptions
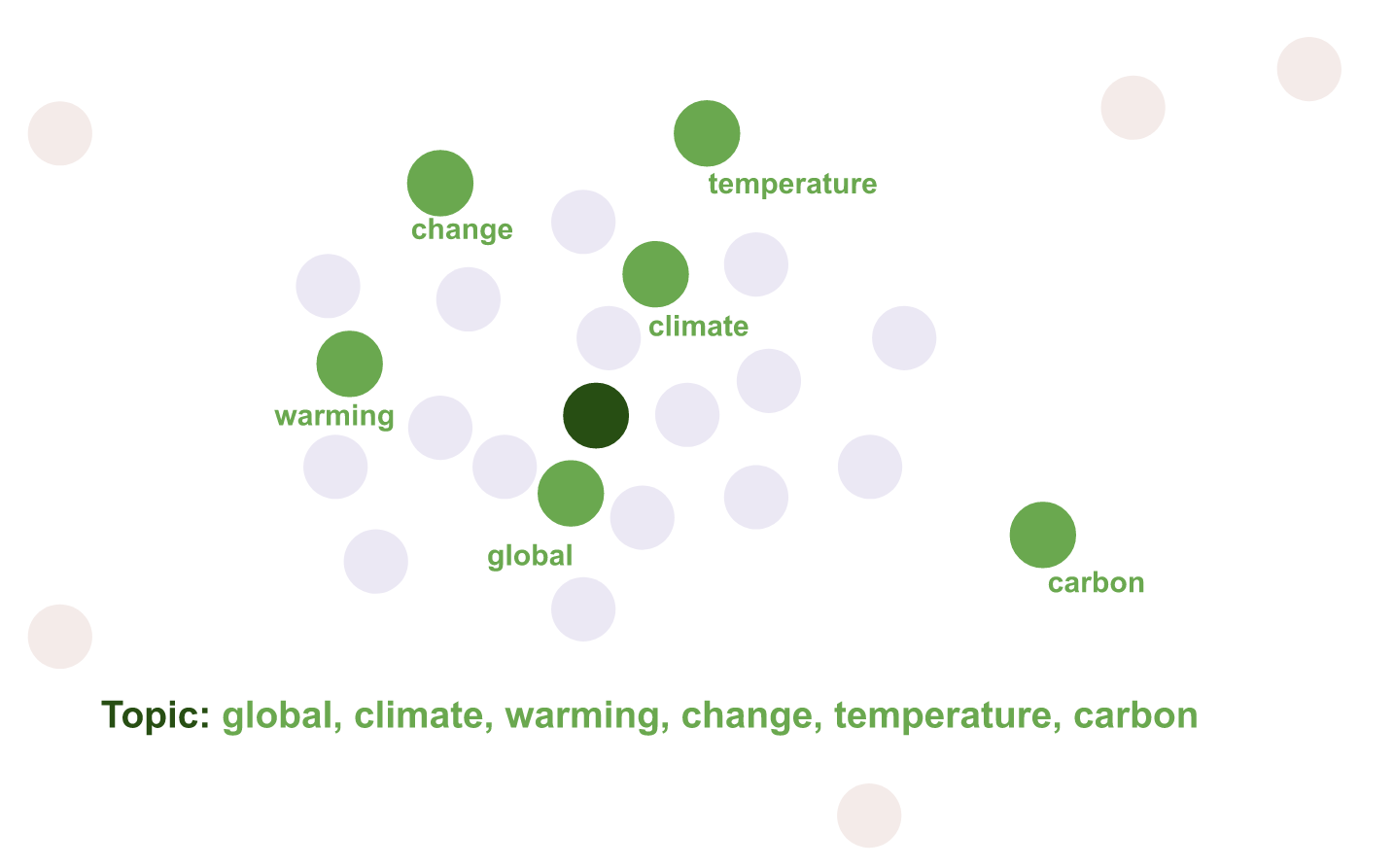
Top2Vec - Summary of the paper
Latent Dirichlet Allocation and Probabilistic Latent Semantic Analysis were the most widely used methods for topic modeling for the past 20 years. However, they rely on heavy pre-processing of the text content (custom stop-word lists, stemming, and lemmatization), and require the number of topics to be known. As a result, results of these approaches are often unstable. Moreover, they rely on bag-of-words representation of documents which ignore ordering and semantics of the words.
The Top2Vec methodology is a fairly recent approach to topic modeling: Top2Vec: Distributed Representations of Topics (August, 2020). The Top2Vec approach leverages recent advances in NLP/Deep Learning: Document and word embeddings from large language models. Besides the NLP improvement (2019), the method incorporates other recent techniques (UMAP for dimensionality reduction, 2018; HDBSCAN for finding density clusters, 2013) to process the embeddings, and obtain the final topics.
The Top2Vec algorithm can be decomposed in 5 steps:
Step 1. Create a joint embedding of documents and words (e.g. using Universal Sentence Encoder or BERT Sentence Transformer)
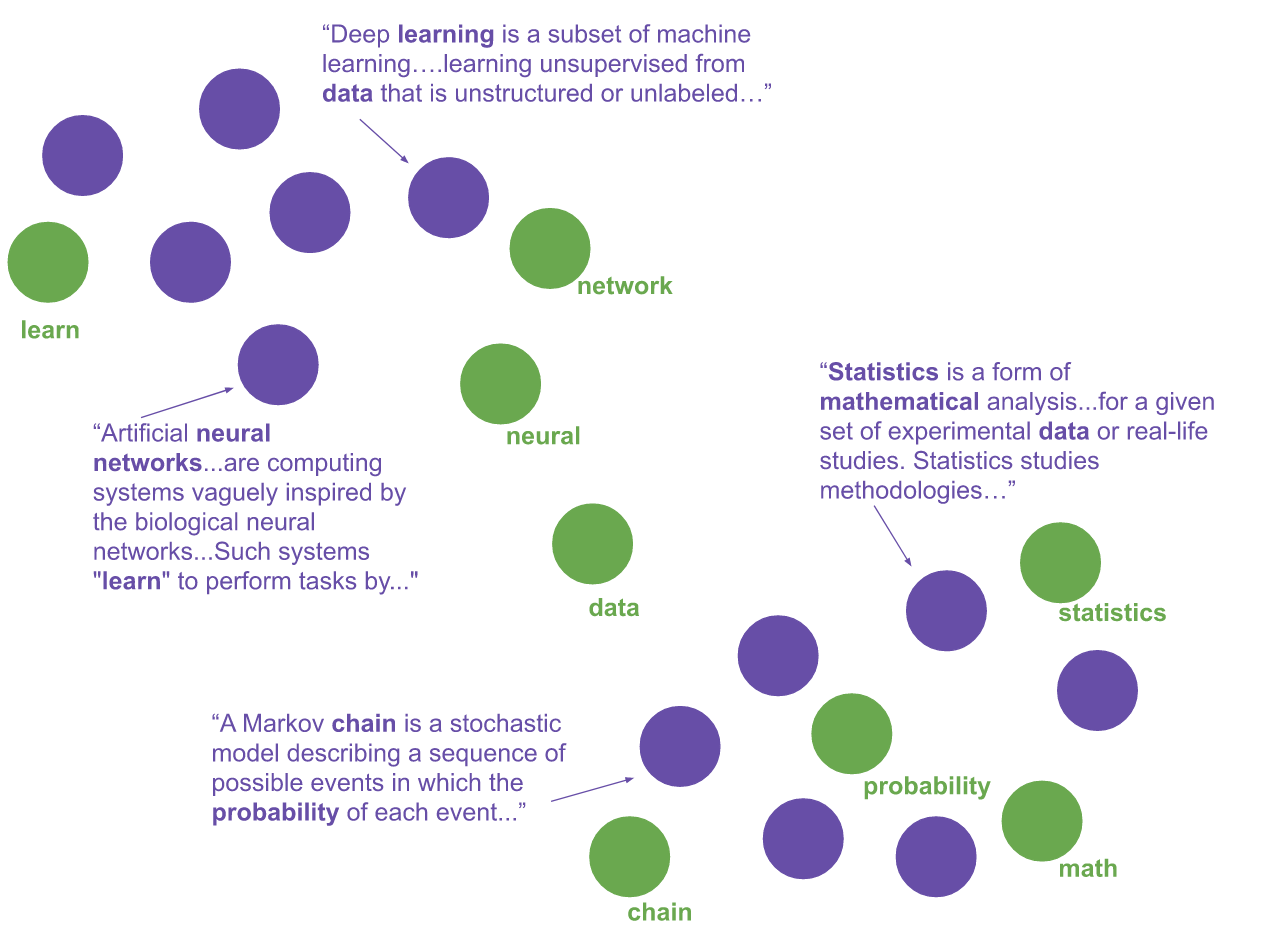
Step 2. Project the document and word vectors to a smaller dimension (e.g. using a dimensionality reduction technique such as UMAP)

Step 3. Find dense clusters (e.g. using a clustering algorithm such as HDBSCAN); a cluster is a topic

Step 4. Find the centroid of each cluster in original high dimension; this centroid is the topic vector
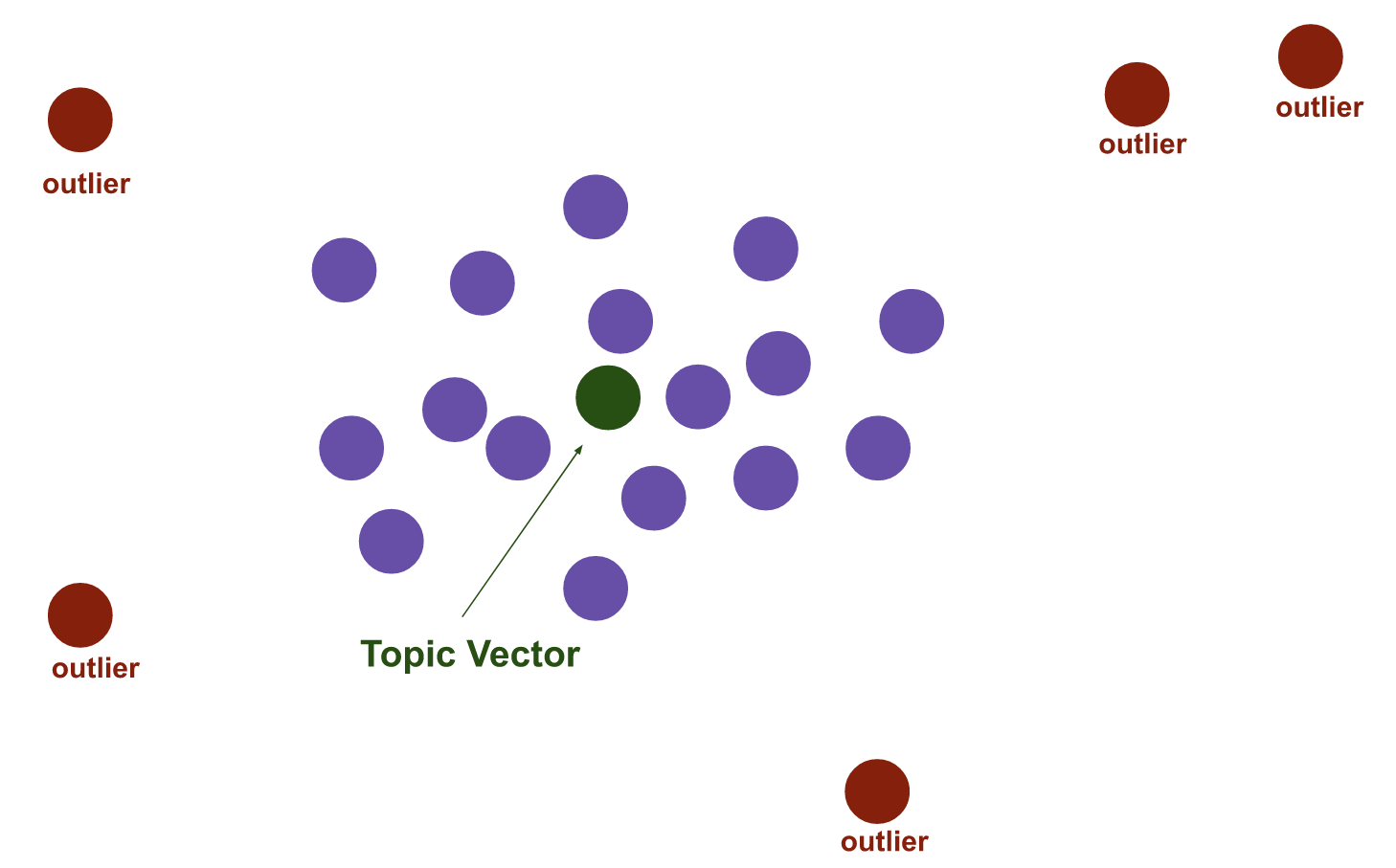
Step 5. Find the n-closest word vectors to the topic vector
Top2Vec GitHub repo with code and examples.
Top2Vec - Application to the 2020 10-K business descriptions
A colab notebook which implements the following steps:
-
Get the ‘Business’ section of the 10-K filings of large US companies (recent members of S&P 500)
-
For each of these 600-ish companies, take its most recent 10-K business description (corresponding to year 2020)
-
Apply Top2Vec on the business descriptions
The algorithm finds 10 topics.
We list the 10 topics below. The topics essentially match sectors. If we were to use the document embeddings and provide a finer clustering, we would recover industries and sub-industries. With many clusters, we can recover very similar companies (e.g. historical and well-known competitors).
Note that Topic 9 is an exception with words such as ‘negatively’, ‘adversely’, ‘inability’, ‘disruption’, ‘unanticipated’ probably due to the covid-19 crisis.
Topics, topic words, and companies:
Topic 1:
['materials',
'aftermarket',
'our',
'beverage',
'manufacturing',
'ametek',
'importance',
'packaging',
'foods',
'industrial']
['dd', 'kmx', 'xom', 'nflx', 'snv', 'ame', 'ipg', 'hrl', 'rsg', 'axp', 'wba', 'cb', 'iqv', 'dlx', 'tdc', 'viav', 'cost', 't', 'abbv', 'l', 'chd', 'orly', 'mro', 'nlok', 'nclh', 'odp', 'pcg', 'atvi', 'pfe', 'jef', 'now', 'it', 'ca', 'khc', 'hon', 'mnst', 'tgt', 'fmc', 'wm', 'mkc', 'ce', 'afl', 'lumn', 'o', 'ph', 'ctlt', 'fb', 'ecl', 'shw', 'emr', 'pkg', 'xel', 'wy', 'pwr', 'pch', 'ppl', 'pfg', 'cms', 'jbht', 'mktx', 'uis', 'klac', 'adp', 'mtg', 'cma', 'nem', 'unh', 'zbh', 'ntap', 'alk', 'rcl', 'tmo', 'mcd', 'ip', 'ci', 'nlsn', 'yum', 'alb', 'lmt', 'gis', 'enph', 'lhx', 'gd', 'csr', 'mdt', 'algn', 'payx', 'rf', 'viac', 'info', 'mmc', 'aapl', 'syf', 'dhi', 'j', 'alxn', 'fcpt', 'len', 'aee', 'met', 'nc', 'disca', 'msft', 'mck', 'mco', 'msi', 'ko', 'xrx', 'fnma', 'wrb', 'cof', 'ppg', 'ftnt', 'ctxs', 'lrcx', 'fmcc', 'emn', 'ual', 're', 'mtb', 'jci', 'mo', 'trmb', 'sbac', 'zts', 'vrsk', 'uaa', 'gild', 'nvda', 'twtr', 'peak', 'cboe', 'tup', 'tjx', 'eqix', 'cf']
Topic 2:
['semiconductor',
'software',
'cloud',
'enterprise',
'technology',
'circuits',
'networking',
'hardware',
'computing',
'silicon']
['ncr', 'hpq', 'rrd', 'jnj', 'mxim', 'mhk', 'nwl', 'chtr', 'unp', 'ir', 'duk', 'wfc', 'hbi', 'fls', 'tdg', 'nke', 'crl', 'dpz', 'noc', 'cci', 'mrk', 'lyv', 'car', 'pvh', 'pnr', 'see', 'pg', 'idxx', 'nee', 'hsic', 'nwsa', 'bac', 'sig', 'bbi', 'big', 'rok', 'cdns', 'rost', 'msci', 'tsco', 'spg', 'tsla', 'adm', 'crm', 'dish', 'goog', 'ilmn', 'ivz', 'leg', 'otis', 'fosl', 'aon', 'ten', 'cprt', 'cbre', 'flr', 'ssp', 'es', 'hpe', 'ed', 'anss', 'tfc', 'cvs', 'ctsh', 'aet', 'mu']
Topic 3:
['clinical',
'pharmaceutical',
'patient',
'healthcare',
'medical',
'drug',
'drugs',
'therapeutic',
'health',
'therapies']
['so', 'well', 'r', 'c', 'bbby', 'pgr', 'aap', 'urbn', 'akam', 'awk', 'rol', 'etr', 'dow', 'dre', 'all', 'pki', 'endp', 'cl', 'cvx', 'ait', 'kmb', 'gnrc', 'mdp', 'pm', 'holx', 'wltw', 'arnc', 'nktr', 'cat', 'pnw', 'fcn', 'pep', 'hp', 'fast', 'pxd', 'tel', 'cnc', 'lly', 'zbra', 'fisv', 'hrb', 'trip', 'mgm', 'bkr', 'fhn', 'vno', 'nov', 'ma', 'ni', 'mtd', 'nyt', 'lw', 'x', 'bio', 'bll']
Topic 4:
['gas',
'natural',
'utilities',
'oil',
'utility',
'ferc',
'pipelines',
'electricity',
'generating',
'pipeline']
['wmb', 'ipgp', 'swks', 'amp', 'prgo', 'hig', 'gra', 'vrtx', 'csco', 'psa', 'pbct', 'pnc', 'tfx', 'hlt', 'mdlz', 'qcom', 'slg', 'dltr', 'dfs', 'stt', 'lvs', 'ebay', 'whr', 'cmcsa', 'lnc', 'tsn', 'lkq', 'uhs', 'are', 'mmm', 'vlo', 'vz', 'wec', 'aiv', 'rig', 'abmd', 'tgna', 'bwa', 'dxc', 'hii', 'swn', 'tkr', 'fox', 'fe', 'cbb', 'adsk', 'mos', 'gpn', 'gt', 'dov', 'amd', 'aiz', 'azo', 'maa']
Topic 5:
['bank',
'banking',
'frb',
'institutions',
'banks',
'depository',
'institution',
'bhc',
'bhcs',
'occ']
['slm', 'mar', 'evrg', 'de', 'txn', 'hban', 'cag', 'hum', 'keys', 'apd', 'an', 'wynn', 'ge', 'anf', 'peg', 'ctva', 'dte', 'mpwr', 'gs', 'pypl', 'incy', 'ftv', 'kss', 'etn', 'dds', 'pru', 'fis', 'rad', 'rtx', 'cmi', 'fslr', 'ato', 'stx', 'cpb', 'irm', 'omc', 'mchp', 'bmy', 'txt', 'penn', 'gpc', 'atge', 'odfl', 'csx', 'payc', 'ea']
Topic 6:
['properties',
'apartment',
'redevelopment',
'tenant',
'tenants',
'estate',
'rents',
'reit',
'rent',
'occupancy']
['vtr', 'exr', 'nue', 'nav', 'vrsn', 'clx', 'czr', 'aal', 'jwn', 'lpx', 'bxp', 'br', 'tap', 'isrg', 'nsc', 'hal', 'f', 'itt', 'jbl', 'low', 'expe', 'ehc', 'sci', 'dgx', 'md', 'wor', 'xec', 'lh', 'reg', 'k', 'vnt', 'efx', 'hd', 'mas', 'cinf', 'a', 'amt', 'kr', 'mtw', 'chrw', 'cern', 'oke', 'nws', 'eix']
Topic 7:
['merchandise',
'stores',
'apparel',
'assortment',
'store',
'merchandising',
'footwear',
'fashion',
'shopping',
'associates']
['bby', 'cog', 'gnw', 'rop', 'unm', 'phm', 'sbux', 'tdy', 'snps', 'spgi', 'cck', 'ndaq', 'lsi', 'slb', 'glw', 'hwm', 'fbhs', 'ctas', 'dg', 'hca', 'adbe', 'abc', 'bco', 'biib', 'anet', 'blk', 'amzn', 'bhf', 'hsy', 'wrk', 'dlr', 'cmg', 'ua', 'has', 'amat', 'hst', 'vfc', 'aep', 'lnt']
Topic 8:
['content',
'programming',
'television',
'video',
'streaming',
'broadcast',
'audience',
'subscribers',
'media',
'audiences']
['uri', 'ice', 'trow', 'lb', 'm', 'hog', 'dis', 'fdx', 'flt', 'ghc', 'lub', 'adi', 'ccl', 'googl', 'ms', 'ess', 'mpc', 'frt', 'iex', 'abt', 'ba', 'mlm', 'amg', 'aph', 'wen', 'aptv', 'orcl', 'mat', 'amgn', 'pld', 'dxcm', 'syy', 'foxa', 'wst', 'ptc']
Topic 9:
['negatively',
'adversely',
'could',
'inability',
'result',
'disruption',
'disruptions',
'corteva',
'affect',
'unanticipated']
['gme', 'amcr', 'ksu', 'tpr', 'vtrs', 'exc', 'nbr', 'bax', 'ati', 'etsy', 'syk', 'ash', 'alle', 'ste', 'ibm', 'kim', 'cfg', 'nvr', 'mac', 'xlnx', 'udr', 'wdc', 'aos', 'fti', 'thc', 'rl', 'key', 'xyl', 'bkng', 'gl', 'iff', 'v', 'itw', 'pdco', 'pbi']
Topic 10:
['insurance',
'insurer',
'policyholders',
'policyholder',
'reinsurance',
'insurers',
'annuity',
'premiums',
'underwriting',
'casualty']
['ajg', 'jkhy', 'lin', 'xray', 'coo', 'wu', 'avb', 'antm', 'dal', 'sun', 'nxpi', 'luv', 'pcar', 'wmt', 'mbi', 'tmus', 'cdw', 'bk', 'zion', 'vmc', 'jnpr', 'fitb', 'cpri', 'regn']
Conclusion: Top2Vec is an easy-to-use tool which can find relevant topics in a corpus of documents. However, the granularity of the topics may not be the most relevant with respect to the applications in mind (e.g. coarse sectors for risk monitoring vs. small groups for mean-reversion trading). Since the embeddings obtained seem to be of good quality, it is possible to use them for re-defining oneself clusters and topics.
Can we residualize topics? Would the residuals be interpretable?