Personal Reflections on NeurIPS 2024

Personal Reflections on NeurIPS 2024
Introduction
I attended NeurIPS 2024 in Vancouver with a few colleagues (Patrik, Kelvin, Lars, and Mathieu), despite the tempting weather and numerous events happening in Abu Dhabi during the winter season; Got a bad cold on the way back. This blog is an attempt to crystallize some of my personal takeaways from the conference, along with potential leads for further exploration. Naturally, it won’t be exhaustive, as I couldn’t attend every session and had other responsibilities to manage during the event. That said, I feel I gained a solid understanding of what had been happening in the fast-paced world of (academic) AI and ML over the past year.
NeurIPS (Neural Information Processing Systems), established in 1987, is one of the most prestigious conferences in artificial intelligence (AI) and machine learning (ML). Over the decades, it has grown into a global hub for researchers, practitioners, and industry leaders to share pioneering work, exchange ideas, and explore cutting-edge advancements. In 2024, NeurIPS reached a historic milestone with nearly 16,000 registrations, cementing its status as the largest academic conference in the field.
Beyond its peer-reviewed papers (talks, posters) and workshops, the event features a dynamic ecosystem of activities, including industry-sponsored events and an expansive sponsor expo (NeurIPS 2024 sponsors). This expo serves as a talent magnet, with companies—ranging from deep tech innovators to hedge funds and proprietary trading firms—eagerly recruiting PhD graduates and top researchers whose work is showcased at the conference. NeurIPS not only shapes the trajectory of AI research but also bridges academia and industry, fueling advancements across technology and finance.
Key Highlights from the Conference
I like to visualize papers on a map to navigate the main themes and find the ones I’m interested in, or even to grasp the broader trends of a conference. For example, I’ve done this for ICML 2024. However, this time, some others have already done a great job capturing the main topics of NeurIPS 2024, so no point duplicating their efforts. Here are two interactive websites that do it well:
 NeurIPS 2024 Papers Map
NeurIPS 2024 Papers Map
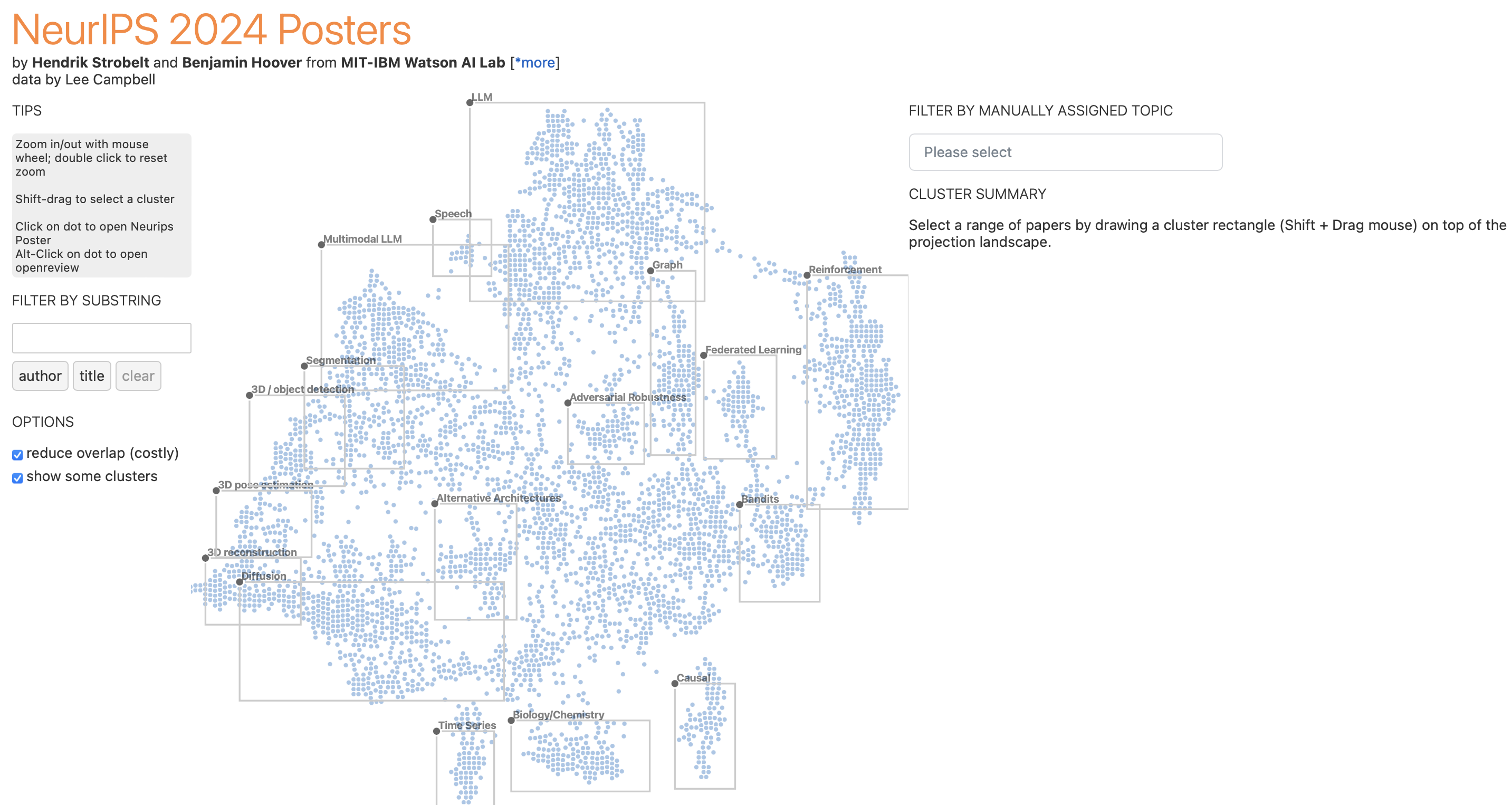 NeurIPS 2024 Papers Map - Official
NeurIPS 2024 Papers Map - Official
I somewhat prefer the ‘non-official’ version: I find it more convenient to navigate the papers by similarity.
Another interesting angle is the specialization by economic/geographic regions, which you can explore in this Sankey diagram.
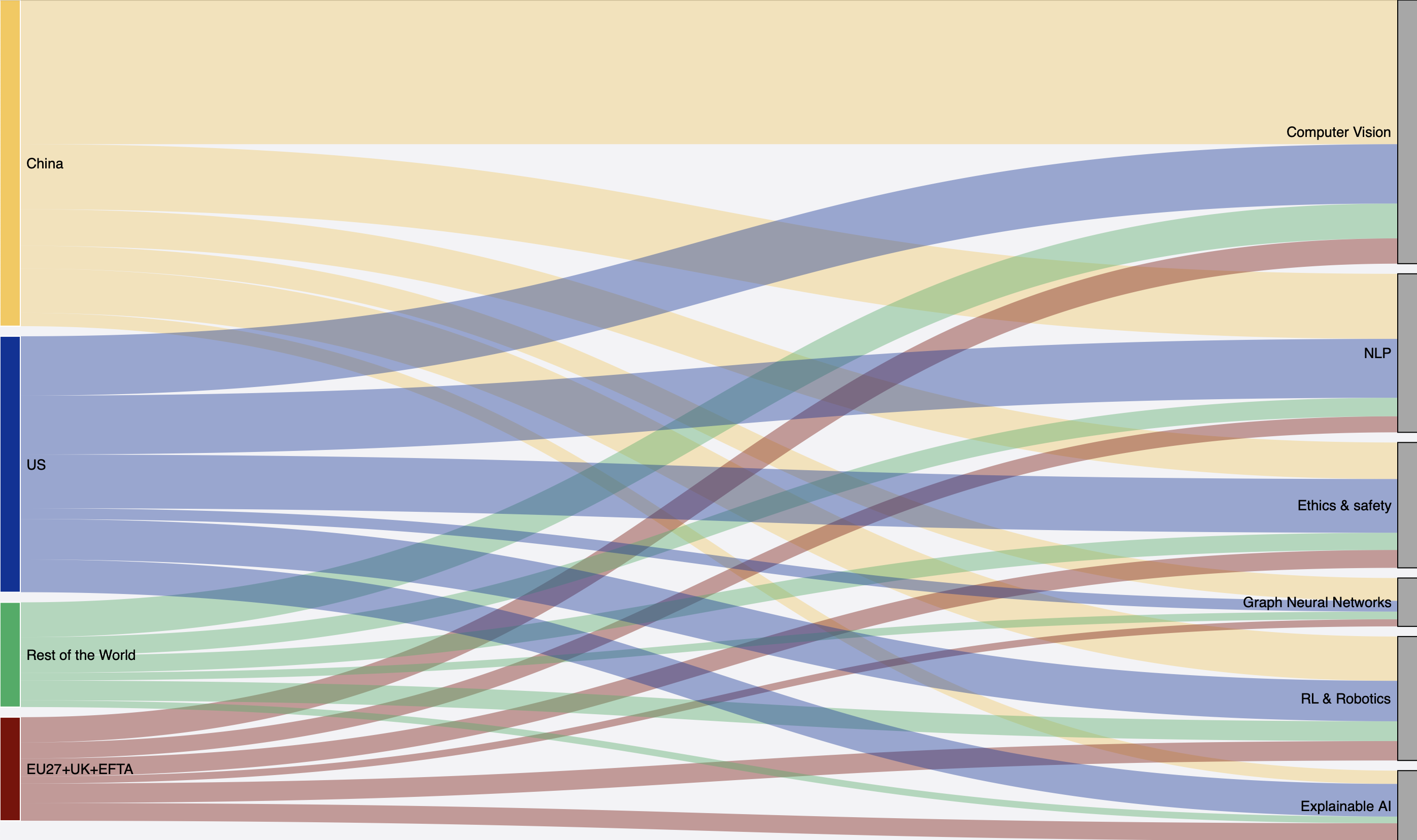 Geographies-to-Topics Sankey
Geographies-to-Topics Sankey
The conference is clearly dominated by China and the USA, which together account for about three-quarters of the papers. It’s unclear what methodology the Sankey uses—whether it attributes papers based on the authors’ university affiliations (likely) or tries to infer their nationalities from names (less likely). This is something I’ve explored before using LLMs to infer demographics from names—if you’re curious, I’ve written about it in this blog. Many papers from US universities are authored by Chinese researchers (or ABCs), highlighting China’s strong influence in AI research.
The specialization by region is also revealing. China stands out in Computer Vision and NLP and has a proportional strength in Graph Neural Networks. China’s dominance in Computer Vision suggests ongoing investments in this field, likely driven by applications in surveillance and autonomous systems. It’s notable that China is on par with the USA in RL & Robotics, but relatively weaker in “Explainable AI.” In contrast, the USA appears well-diversified across all sub-fields. Europe, while contributing fewer papers, shows a relatively stronger focus on “Explainable AI” and “Ethics & Safety.”
What’s missing? A good visualization illustrating the evolution of topics over time. I remember 10 years ago, it was all about supervised ML, structured predictions, dealing with missing and noisy labels, and active learning. Can we trace the transition from this focus on efficient labeling to the current zero-shot and few-shot paradigms? What caused some topics to fade away completely—were they trivialized by newer approaches? And do these newer paradigms fully subsume the older problems, or is it a case where they solve only certain aspects while the community shifts focus due to trends and “mode effects”?
Maybe I’ll take this up as a weekend project at some point—not super practical, but it would be fun to visualize how the field has evolved over the past 10–15 years just out of curiosity.
NeurIPS 2024 revealed some clear directions in AI/ML research. Multimodality continues to be a major focus, with researchers exploring how to integrate text, audio, video, and other modalities more effectively. Efficiency in LLMs is another prominent theme, whether through compression techniques, new architectures, or advances in inference. The role of reinforcement learning is also evolving—often intertwined with LLMs—to improve fine-tuning and enable more interactive applications. These trends highlight the ongoing balance between theoretical advancements and practical applications in the field.
Building on these broader trends, below are some of my personal takeaways and areas I found particularly interesting at NeurIPS 2024.
Personal Takeaways
Staying up-to-date in the field is a lot of work—it moves incredibly fast. It’s impossible to keep track of all the research, especially since a lot of it will turn out to be less relevant, follow wrong paths, or quickly get subsumed by superior models and approaches. Many ideas presented today will be discarded in the coming years as they are beaten by better solutions. Still, it’s a valuable exercise to try to understand and predict which pieces of work will be influential for the future of the field. I should probably commit to a fixed list for each conference—it’s too easy to ‘back trade’ and claim “I knew it!” after the fact. Feels a bit like stock picking, doesn’t it?
LLMs were, unsurprisingly, a major focus of the conference, often tying into more classic areas of ML. For instance, there were several papers exploring LLMs in combination with Reinforcement Learning (RL). If you look at the thematic map (below), you can see how LLMs subdivide into various sub-categories and connect with other branches of ML, such as privacy/security/adversarial attacks, multimodality, and alternative learning paradigms. One particularly interesting area is the investigation of using Transformers for state-space models, traditionally dominated by methods like Kalman filters.
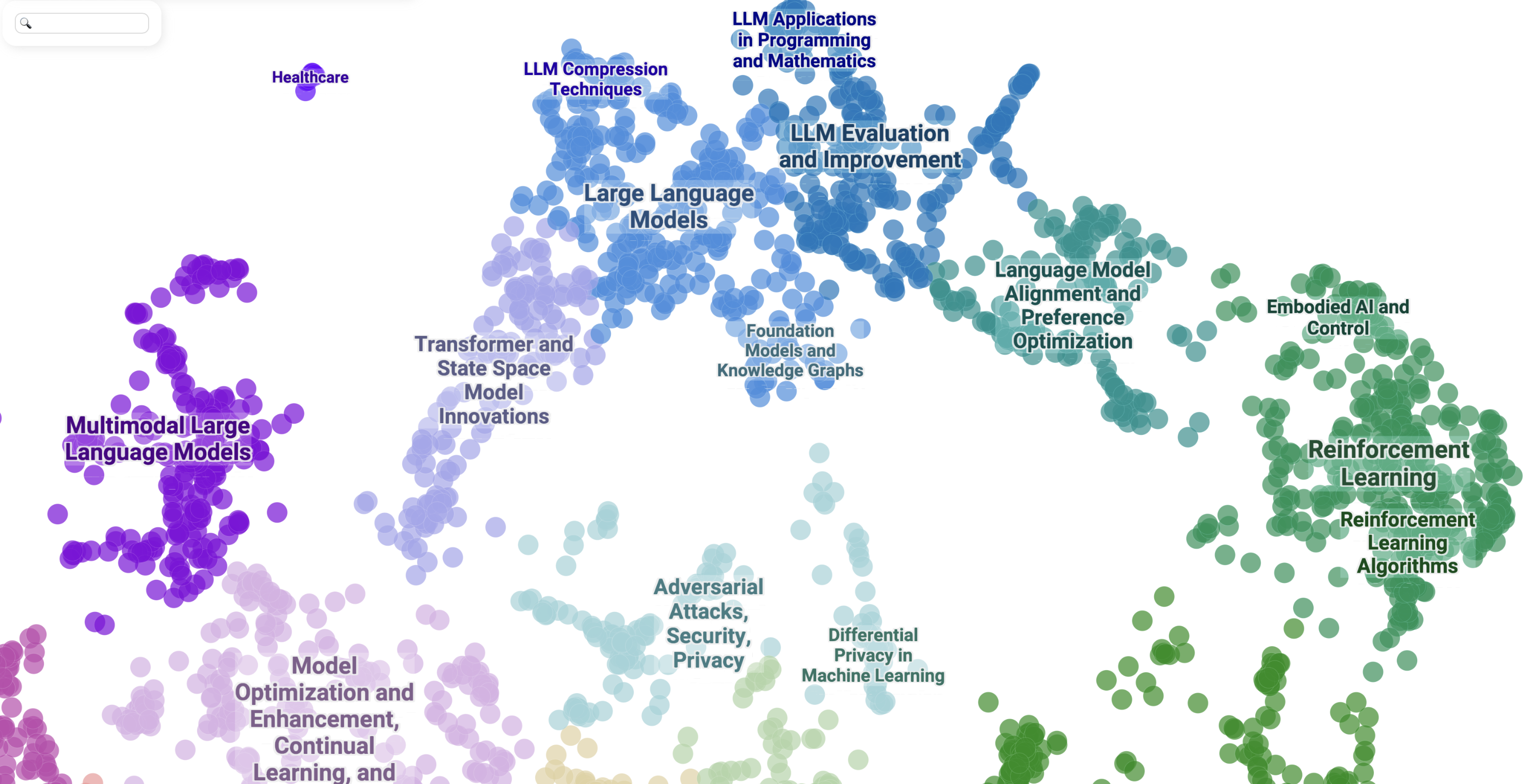 NeurIPS 2024 Papers Map - Focus on LLMs
NeurIPS 2024 Papers Map - Focus on LLMs
There were also lots of papers on applying LLMs to tackle mathematical and algorithmic problems, as well as in coding/programming tasks, like code generation and programming assistants. The industry is already seeing widespread adoption here—think Microsoft’s GitHub Copilot. The papers in this space seem to focus on pushing beyond the current capabilities or identifying and addressing corner cases that need more attention.
Another standout topic was LLM Compression Techniques, which focus on reducing the size, computational requirements, and memory footprint of large models while preserving as much of their performance as possible. The implications are obvious—lower costs, easier deployment in low-resource environments (like edge devices), and improved energy efficiency, which aligns with broader goals of sustainability. This area is crucial given how resource-hungry LLMs can be (GPUs/TPUs don’t come cheap, and energy costs are a concern for large-scale adoption). The emphasis on this topic shows the growing demand for solutions that make LLMs more accessible and environmentally sustainable.
Interestingly, the focus on efficient inference was reflected in the presence of several companies showcasing fast inference hardware, like Cerebras, D-Matrix, and SambaNova. Surprisingly, Groq wasn’t there—or at least I didn’t spot them.
NeurIPS isn’t typically the go-to conference for deep dives into knowledge graphs (KGs), but there were still some interesting contributions, particularly in how LLMs and KGs interact. For example, papers like KG-FIT: Knowledge Graph Fine-Tuning Upon Open-World Knowledge explore how LLMs can integrate with KGs, enriching their ability to reason over structured and unstructured data.
LLMs themselves can be thought of as fuzzy lookup tables or compressed knowledge bases, as they inherently store and compress vast amounts of the world knowledge they’re exposed to during training (cf. Hochreiter’s slide below). However, their “fuzziness” makes them less precise than KGs when it comes to exact reasoning, which is why the two technologies often complement each other.
 LLMs are like databases - Sepp Hochreiter
LLMs are like databases - Sepp Hochreiter
Another promising direction is the use of LLMs to build, maintain, and enhance ontologies or KGs—tasks that have traditionally been labor-intensive and require substantial manual effort. LLMs can help automate ontology learning, as seen in End-to-End Ontology Learning with Large Language Models, or assist with challenges like entity alignment despite noisy data (Entity Alignment with Noisy Annotations from Large Language Models).
The synergy between KGs and LLMs is notable because it bridges the precision of symbolic representations with the adaptability and generalization of neural models. Whether fine-tuning LLMs on KGs, using LLMs to extract and structure knowledge, or leveraging KGs to ground LLMs for better factual accuracy, this interplay is likely to grow into a critical subfield of AI research.
Another relatively significant chunk of papers at the conference focused on the theme of transformers for state space models (SSMs). The potential applications are broad, spanning time-series forecasting, control systems (e.g., dynamic modeling for robots or autonomous vehicles), and signal processing. This stream of research aims to merge the strengths of traditional SSMs, which excel at handling latent states and noise in dynamical systems, with transformers, known for their ability to model long-range dependencies and complex, non-linear relationships.
The idea is intriguing—by blending these paradigms, researchers hope to create models that are both expressive and interpretable, leveraging the strengths of both approaches. While transformers have revolutionized sequence modeling, they face challenges like high resource demands and limited interpretability, which this hybrid approach could potentially address.
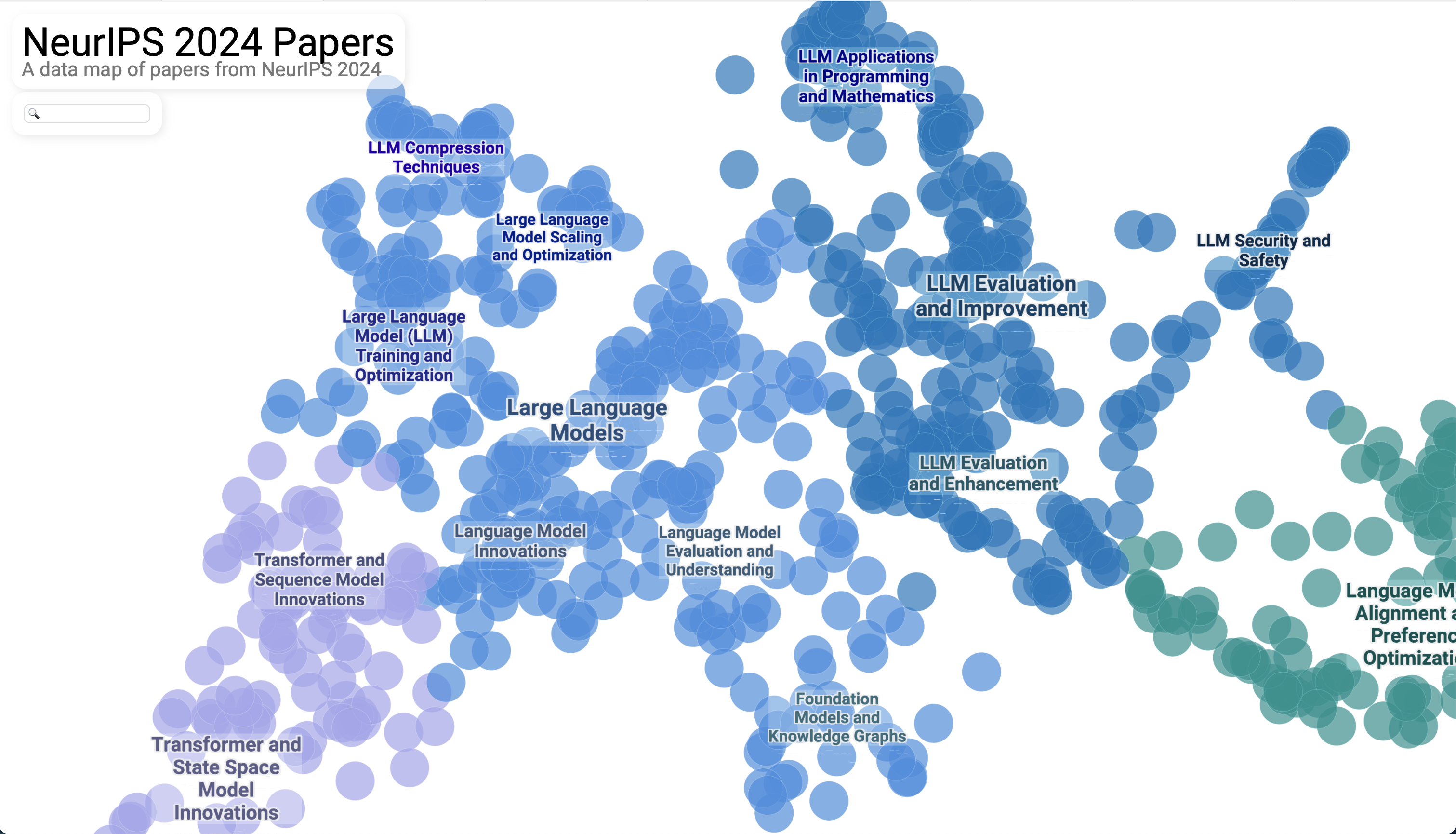 Transformers for state space models
Transformers for state space models
Mamba: A New Competitor to Transformers?
One particularly interesting development in this space is the emergence of Mamba, a relatively recent architecture introduced on December 1, 2023. Despite its youth, Mamba already has more than two dozen papers accepted at NeurIPS 2024 leveraging the architecture, suggesting it’s gaining traction rapidly. Could Mamba-like models represent the next trend in sequence modeling? It’s too early to tell, but the pace of adoption at this year’s NeurIPS hints at strong interest.
Mamba is positioned as an alternative to transformers, specifically designed to improve efficiency and interpretability for tasks where sequence modeling intersects with dynamical systems. This architecture seeks to address some of the computational and scalability challenges of transformers while retaining their ability to handle complex dependencies.
While I’m not deeply familiar with this literature yet, it’s clear that Mamba and transformer-SSM hybrids are generating a lot of excitement. There seems to be real potential here, not just for theoretical advancements but for practical applications in areas like economic and financial time-series forecasting or autonomous systems. I should probably find the time to catch up on this literature, as it feels like a promising development. Will Mamba-like models carve out a niche alongside or even rival transformers?
I’ve bookmarked a handful of papers that caught my attention and seem relevant for understanding Mamba and its applications. I might read them later… These include:
- The Mamba in the Llama: Distilling and Accelerating Hybrid Models
- MambaLRP: Explaining Selective State Space Sequence Models
- The Expressive Capacity of State Space Models: A Formal Language Perspective
LLM-based agents are an exciting and rapidly growing trend in research, with significant promise for industrial applications. These agents leverage the capabilities of large language models to perform complex, autonomous tasks across various domains. The flexibility and generalization capabilities of LLMs make them a strong candidate for automating workflows, enabling better decision-making, and even simulating human-like collaboration. Below are some key themes and papers on this topic that stood out:
LLMs as Urban Agents:
- Large Language Models as Urban Residents: An LLM Agent Framework for Personal Mobility Generation: This paper explores LLM-based agents in the context of urban mobility, treating them as “virtual residents” to generate and simulate personal mobility patterns. These applications hold potential for urban planning, traffic management, and optimizing public transport systems. While similar use cases have been studied in agent-based modeling literature, they often rely on simpler, non-LLM-based agents. The novelty here lies in incorporating LLM-based agents into the modeling process, enabling more sophisticated and adaptable simulations.
Coding and Bug-Fixing Agents
- SWT-Bench: Testing and Validating Real-World Bug-Fixes with Code Agents: Investigates the use of LLM-based agents for testing and validating software bug fixes, providing insights into how autonomous agents can improve software reliability.
- MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue ReSolution: MAGIS introduces a team of four specialized agents: a Manager, Repository Custodian, Developer, and Quality Assurance Engineer, each tailored for different aspects of software evolution. This multi-agent setup demonstrates how LLMs can coordinate complex, collaborative workflows in software development.
Data Science and Workflow Automation
- Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?: This paper provides a sobering look at the limitations of current multimodal agents, particularly in automating data science workflows. According to the authors, these agents still struggle with GUI interactions, highlighting the challenges of translating high-level language capabilities into precise, context-sensitive actions.
- Star-Agents: Automatic Data Optimization with LLM Agents for Instruction Tuning: Focuses on optimizing data for instruction tuning through LLM-based agents, demonstrating their utility in automating large-scale data preprocessing and curation tasks.
Multi-Agent Environments
AdaSociety: An Adaptive Environment with Social Structures for Multi-Agent Decision-Making: Explores the design of adaptive environments where multiple LLM-based agents interact with social structures to solve decision-making problems. The emphasis on social dynamics and collaboration adds a layer of complexity, mimicking real-world team interactions.
Financial Decision-Making
FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making: FinCon employs a hierarchical structure with Manager and Analyst agents collaborating through natural language interactions. The system generalizes across financial tasks, including single-stock trading and portfolio management, showcasing the potential of LLM-based agents in quantitative finance.
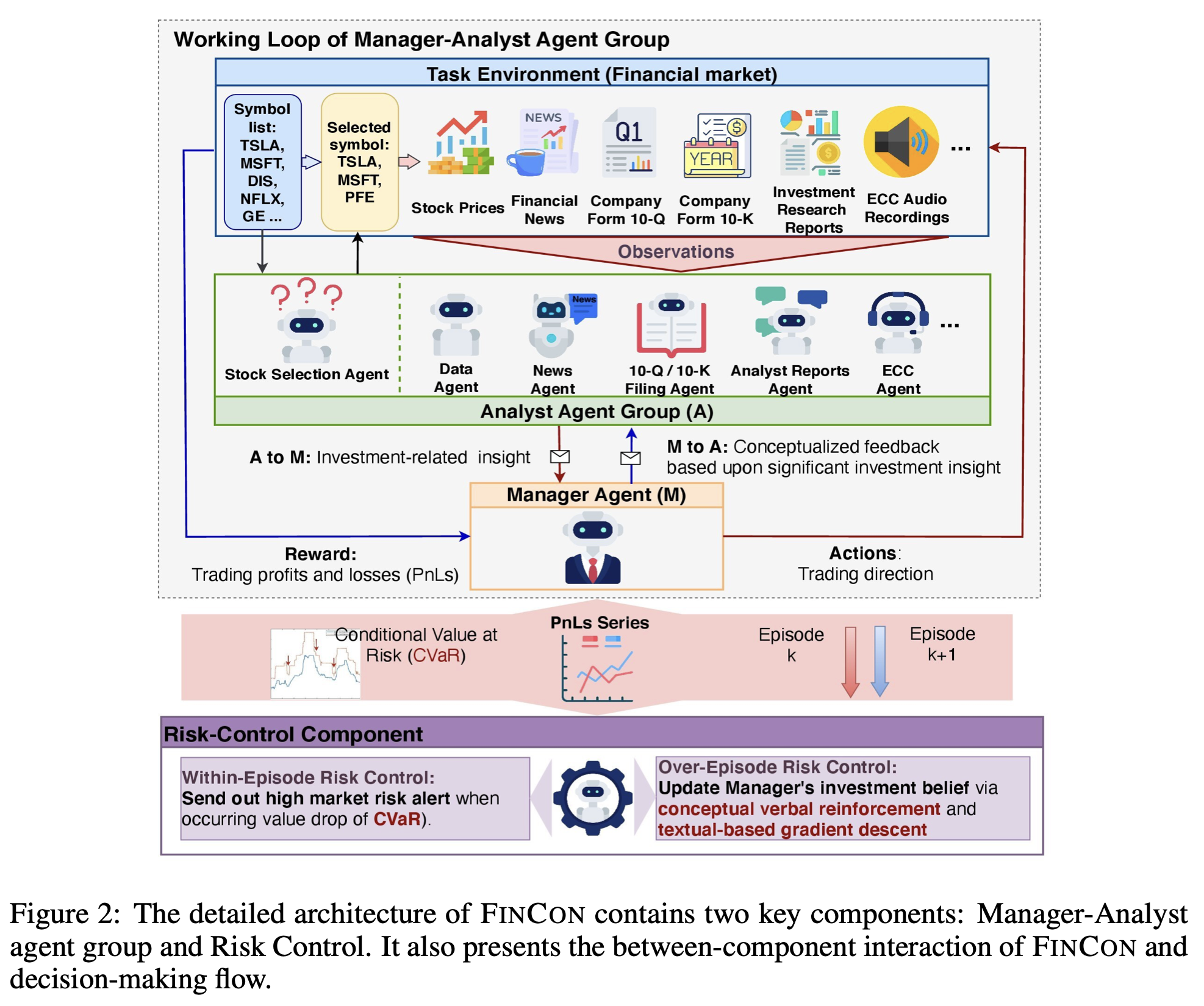 Manager and Analyst agents - Automating the pod model?
Manager and Analyst agents - Automating the pod model?
Before LLM-based agents took center stage, the main “agents” discussed at ML conferences were those built on Reinforcement Learning (RL). As can be seen on the conference papers map, these two sub-fields are increasingly intertwined. Many RL agents now incorporate LLMs either as a core component or as part of their input pipeline. LLMs provide these agents with enhanced natural language understanding, which allows them to process unstructured or complex instructions, interact with users more naturally, and even reason in ways that traditional RL agents struggle with.
Interestingly, this interaction works in both directions. RL is not just a consumer of LLM capabilities—it’s also a tool for improving or aligning LLMs. Techniques like Reinforcement Learning from Human Feedback (RLHF) have been key to fine-tuning LLMs for tasks that require alignment with human values or preferences, such as making conversational agents more polite or factual.
The multimodal large language model (LLM) space is a growing area of research, evident from a distinct cluster of papers in the NeurIPS papers map. These models sit at the intersection of traditional LLMs (text-based) and systems designed for text-to-image and text-to-video generation. Among the various approaches, researchers are focusing on both speed improvements and expanding multimodal capabilities, including audio, visual, and temporal understanding.
Some papers tackle audio-visual learning, addressing how to combine spoken language with visual cues for tasks like captioning, transcription, and video understanding. There is also interest in audio-only tasks, though these remain a niche area within NeurIPS, as ICASSP (International Conference on Acoustics, Speech, and Signal Processing) is the more dedicated venue for such research.
Video-based LLMs (VLMs) are emerging as a focal point. These models aim to integrate textual descriptions with video inputs to build temporal understanding. However, this remains a challenge due to the complexity of aligning text with dynamic, multi-frame video content. Temporal coherence—understanding events in sequence—is an area where significant progress is needed.
Generating videos remains one of the hardest tasks in multimodal modeling. Many systems struggle to respect common physics, such as gravity or object permanence, leading to outputs that break realism. Despite these flaws, improvements in video-language models (VLMs) signal progress, and this area remains an active focus of the AI/ML community.
Modeling text, audio, and video together remains a complex task due to the differences in data structure, scale, and temporal characteristics of these modalities. While progress is being made, truly unified multimodal models are still at an early stage. Advancements in architecture design, pretraining strategies, and computational efficiency will likely be needed to handle these challenges effectively.
Multimodal data remains an underutilized source of knowledge. Current LLMs are thought to have covered much of the publicly available text-based data, and future improvements in AI understanding may depend on incorporating other modalities:
-
Audio: Podcasts and expert discussions capture nuanced information and perspectives not commonly available in written form.
-
Video: Videos contain knowledge about the physical world, including motion, spatial relationships, and common-sense physics, which text-based models cannot fully grasp.
If models like VLMs improve their ability to integrate and analyze these modalities, they could lead to better internal representations and broader applications in areas like robotics, education, and healthcare.
While multimodal LLMs are growing, diffusion models remain a prominent area of research, particularly in image generation. These models dominate this domain due to their ability to generate high-quality, high-resolution images.
A notable trend is the rise of Diffusion Transformers, which combine diffusion processes with the attention-based capabilities of transformers. These models are proving to be highly effective for generating detailed, structured images. However, new challengers like Diffusion Mamba are emerging, potentially offering a more efficient alternative to the transformer-based architecture.
Despite the ongoing dominance of diffusion models in image generation, GPT-like autoregressive (AR) models are now surpassing diffusion transformers in certain settings. Notably, the paper Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction received the NeurIPS Best Paper Award for its groundbreaking work. This research highlights how AR models can achieve state-of-the-art results in image generation by leveraging scalability and precision in next-pixel or next-scale predictions.
It has been a while—probably about five years—since I last followed the developments in Graph Neural Networks (GNNs), and NeurIPS 2024 gave me a useful update on how the field has evolved. GNNs are no longer confined to traditional message-passing paradigms; instead, the field has diversified into new architectures, scalability methods, and integration with other models like LLMs.
As a quick refresher, GNNs aim to predict various properties or relationships in graphs, tackling tasks like node classification, link prediction, graph classification, graph regression, dynamic graph prediction, and even graph generation. Graphs—or networks, as they’re often called in social sciences—are everywhere in science and industry, with applications ranging from fraud detection and drug discovery to marketing and social network analysis.
One interesting direction is the development of “universal” GNNs—models designed to generalize across different types of graphs and tasks. This feels a bit like the “GPT moment” in NLP, where the goal is to create a general-purpose model. Papers like ProG: A Graph Prompt Learning Benchmark and RAGraph: A General Retrieval-Augmented Graph Learning Framework explore this idea. That said, the concept still seems far from realization. Graph data can vary a lot—from molecular graphs to social networks—so building a one-size-fits-all solution is a tough challenge.
To dig deeper, I bookmarked a few more papers that caught my attention during the conference. These papers span foundational tasks, interpretability, and novel methods in GNNs:
-
Foundational Tasks: Mixture of Link Predictors on Graphs
-
GNNs and LLMs: LLMs as Zero-shot Graph Learners: Alignment of GNN Representations with LLM Token Embeddings
-
Interpretability: The Intelligible and Effective Graph Neural Additive Networks
And, finally, a potentially useful trick for the practitioner: Probabilistic Graph Rewiring via Virtual Nodes.
Overall, there is about five years of research to catch up on. It will be interesting to see whether graphs or time-series models will achieve their “universal” moment first—if such a thing is even possible for either field.
GNNs and causality appear close in the NeurIPS 2024 papers map, as both fields rely heavily on graphs—directed acyclic graphs (DAGs) in the case of causality. GNNs focus on modeling complex relationships and interactions in networks, often with a prediction angle, whereas causality shifts the focus to uncovering and quantifying cause-and-effect relationships, leaning more towards explanation.
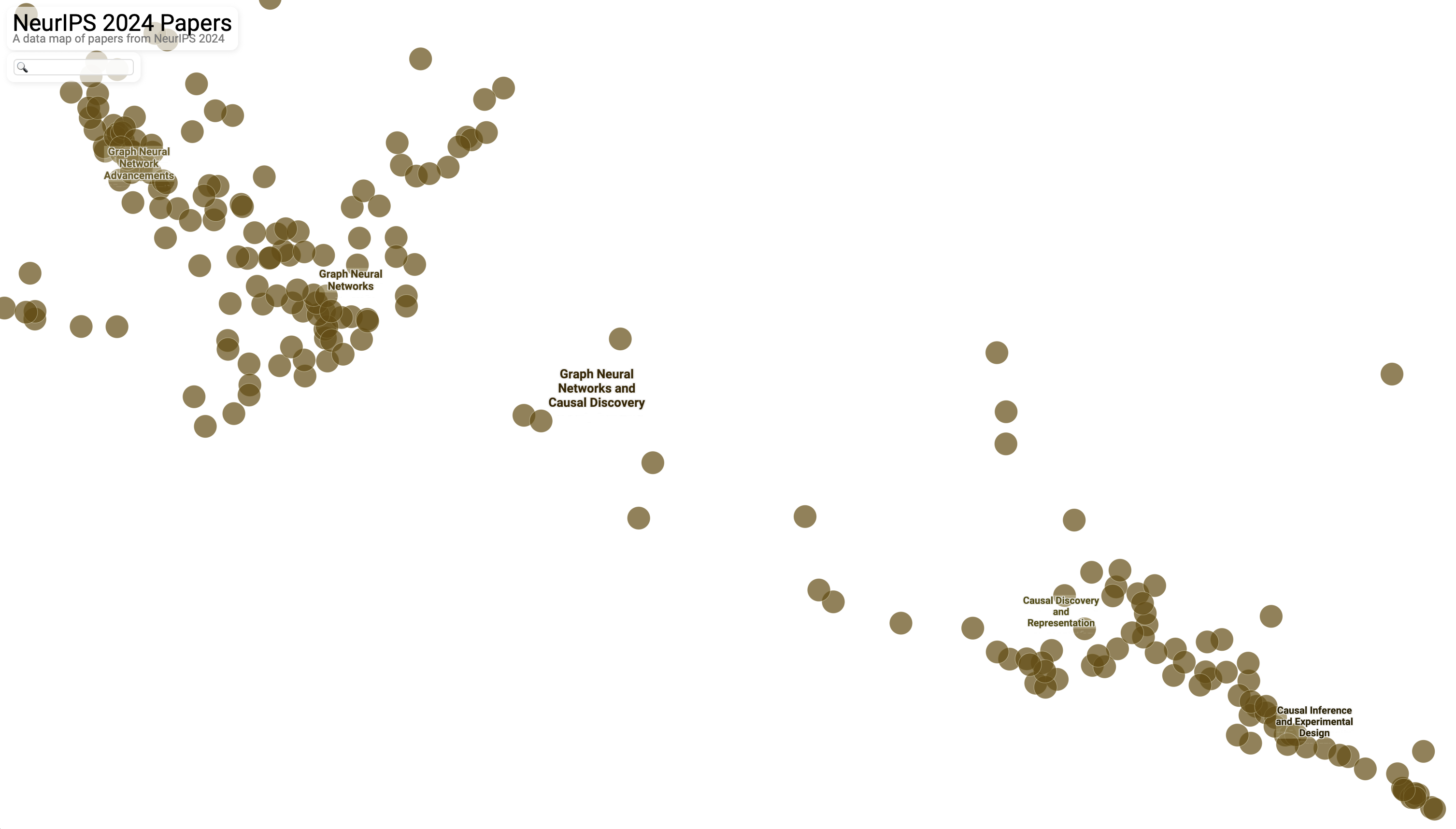 GNNs and Causal AI
GNNs and Causal AI
Within the causality cluster, there’s a clear split: Causal Discovery and Representation is positioned closer to GNNs, while Causal Inference and Experimental Design sits further away. This reflects the focus of each area—causal discovery often involves graph-based methods to uncover relationships, while causal inference is more about estimating effects once a causal structure is known.
 Causal Discovery vs. Causal Inference - NeuRIPS 2024 Tutorial
Causal Discovery vs. Causal Inference - NeuRIPS 2024 Tutorial
Causal discovery tries to answer the question, “What causes what?” It works on identifying relationships between variables, often using observational data, and aims to represent these as a DAG or similar graphical structure. Causal inference, on the other hand, answers, “How much does X affect Y?” It focuses on quantifying effects under interventions and testing the robustness of those conclusions. Together, they form a complementary loop: discovery generates hypotheses about causality, and inference tests and refines them.
While I don’t actively use causal discovery methods in my work, I’ve picked up some high-level insights from colleagues who specialize in this area. For domains where interventions are difficult or impossible, causal discovery becomes the primary focus. However, finding robust results in practice is incredibly challenging. It would be useful to see a systematic review ranking the applications of causal discovery methods from “easy” to “hard/not yet applicable”. I don’t have the bandwidth to experiment widely, but clarifying where the field stands in terms of practical applications would be helpful.
Causal discovery is an exciting area because of its potential to improve both interpretability and robustness in AI systems. Its applications span a wide range of fields, from healthcare to economics. A few papers and tools in this space caught my attention:
- Causal-learn: Causal Discovery in Python: A Python library designed to make causal discovery more accessible.
- Causal Dependence Plots: This approach visualizes how an outcome depends on changes in a predictor, along with the subsequent causal changes in other predictors.
- Do causal predictors generalize better to new domains? Predictors using all available features, regardless of causality, have better in-domain and out-of-domain accuracy than predictors using causal features (!).
- Discovery of the Hidden World with Large Language Models A paper showing how LLMs and causal discovery methods can complement each other in factor proposals.
- Causal vs. Anticausal merging of predictors Authors show that if we observe all bivariate distributions, the CMAXENT solution reduces to a logistic regression in the causal direction and Linear Discriminant Analysis (LDA) in the anticausal direction.
Overall, while the theoretical tools in causal discovery are advancing, applying them effectively in real-world scenarios seems to remain a big challenge. It’s an area worth watching.
Moving from causality to another application-driven area, healthcare stood out as a distinct cluster on the NeurIPS 2024 map, positioned between ‘Large Language Models’ and ‘Multimodal Large Language Models,’ with 14 papers focused on LLM applications in medicine.
 AI for Healthcare
AI for Healthcare
Healthcare has long been a major user of applied causality, particularly through RCTs (randomized controlled trials) and causal inference methods. What’s new in these NeurIPS contributions is the focus on leveraging LLMs and introducing novel benchmarks. These papers primarily explore how LLMs can assist in medical tasks while starting to touch on some notion of causality—especially in understanding and reasoning about the decisions made by these models in high-stakes environments like medicine.
Interestingly, this highlights a potential convergence: while healthcare has historically used causality to ensure robust and interpretable outcomes, the next step may involve integrating causality into LLMs themselves. This is an active area of research, and it was even explored in a NeurIPS 2024 tutorial (picture below).
 LLMs and Causality - NeuRIPS 2024 Tutorial
LLMs and Causality - NeuRIPS 2024 Tutorial
While I don’t work in this area (data science for healthcare), it’s of interest to ADIA Lab—an independent laboratory dedicated to data and computational sciences. Exploring these works could inspire research collaborations or yield practical insights.
What makes this collection particularly interesting is its focus on practical constraints and high-stakes decision-making, hallmarks of the medical field. Strict data privacy regulations, the need for interpretable models, and the severe consequences of errors set a high bar for performance. These challenges force researchers to design rigorous benchmarks and address real-world usability, offering valuable lessons for other domains where decisions carry material consequences.
Across these papers, several common themes emerge: improving the interpretability and reliability of LLMs, designing benchmarks tailored to medical tasks, and addressing safety, bias, and real-world usability. Here’s a brief overview of the contributions:
- Uni-Med: A Unified Medical Generalist Foundation Model For Multi-Task Learning Via Connector-MoE A multi-task model integrating six medical tasks, from question answering to image classification.
- PediatricsGPT: Large Language Models as Chinese Medical Assistants for Pediatric Applications The first pediatric-specific LLM for Chinese medical applications.
- MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making A multi-agent framework for collaborative decision-making, excelling in multi-modal reasoning tasks.
- MediQ: Question-Asking LLMs and a Benchmark for Reliable Interactive Clinical Reasoning A system designed for question-asking to improve reliability in clinical reasoning.
- Instruction Tuning Large Language Models to Understand Electronic Health Records Focuses on improving LLM performance in answering EHR-related patient queries.
- DiReCT: Diagnostic Reasoning for Clinical Notes via Large Language Models A dataset for evaluating diagnostic reasoning and interpretability compared to human doctors.
- A teacher-teacher framework for clinical language representation learning A framework for aligning pre-existing models to better represent clinical notes.
- MedJourney: Benchmark and Evaluation of Large Language Models over Patient Clinical Journey A benchmark covering four stages of a patient’s clinical journey, with tasks across 12 datasets.
- MEDCALC-BENCH: Evaluating Large Language Models for Medical Calculations Focused on evaluating LLMs’ ability to perform medical calculations, highlighting their current limitations in clinical settings.
- EHRNoteQA: An LLM Benchmark for Real-World Clinical Practice Using Discharge Summaries A benchmark built on discharge summaries, evaluating LLM performance in answering patient-specific questions.
- EHRCon: Dataset for Checking Consistency between Unstructured Notes and Structured Tables in Electronic Health Records A framework for verifying consistency in EHRs.
- MedSafetyBench: Evaluating and Improving the Medical Safety of Large Language Models A benchmark dataset measuring medical safety in LLMs, emphasizing fine-tuning for improved performance.
- SM3-Text-to-Query: Synthetic Multi-Model Medical Text-to-Query Benchmark A benchmark of diverse natural language queries for medical tasks.
- Cross-Care: Assessing the Healthcare Implications of Pre-training Data on Language Model Bias Highlights biases in LLMs’ disease prevalence representation across demographics.
These papers demonstrate the ongoing efforts to create safe, interpretable, and practical AI systems for healthcare. Even for those outside the domain, the rigor and high standards required for medical applications can serve as a model for developing AI in other critical areas.
Climate science is another area of focus for ADIA Lab, which has a natural interest in understanding long-term environmental trends and their impacts.
What’s the difference between climate and weather? In simple terms, weather describes the short-term atmospheric conditions in a specific place—think hours to days. Climate, on the other hand, is the average of weather conditions over a much longer period, typically decades or centuries. While weather forecasts tell you if it will rain tomorrow, climate models help predict long-term changes like global warming or shifts in precipitation patterns.
Climate papers:
- Validating Climate Models with Spherical Convolutional Wasserstein Distance Introduces a method to measure differences between climate models and reanalysis data, ensuring better model validation.
- ChaosBench: A Multi-Channel, Physics-Based Benchmark for Subseasonal-to-Seasonal Climate Prediction Proposes a benchmark to extend predictability from weeks to months, filling a crucial gap in climate forecasting.
- Probabilistic Emulation of a Global Climate Model with Spherical DYffusion Explores whether the success of data-driven methods in weather forecasting can extend to the complexities of climate modeling.
Weather papers:
- Personalized Adapter for Large Meteorology Model on Devices: Towards Weather Foundation Models Introduces LM-WEATHER, a model outperforming state-of-the-art results across tasks like forecasting and imputation.
- Generalizing Weather Forecast to Fine-grained Temporal Scales via Physics-AI Hybrid Modeling Combines physics for large-scale weather patterns with AI for adaptive corrections, achieving state-of-the-art performance at multiple timescales.
- Probabilistic Weather Forecasting with Hierarchical Graph Neural Networks Combines latent-variable modeling with graph-based forecasting for more flexible and reliable probabilistic weather predictions.
- Scaling transformer neural networks for skillful and reliable medium-range weather forecasting A transformer-based model delivering state-of-the-art performance, especially beyond 7-day forecasts, while using significantly less training data and compute.
These papers highlight the growing integration of physics-informed AI and advanced deep learning methods in tackling the challenges of both weather and climate prediction.
There were several other topics at NeurIPS 2024 that I didn’t dive into, such as molecular and quantum computing, autonomous driving, and low-level optimization techniques for ML models. While these areas are undoubtedly interesting and important, they are a bit far from my current interests and expertise.
What’s next?
Looking back at NeurIPS 2024, there are plenty of ideas to dig into and explore further. Here’s what I plan to focus on next:
- Reach out to some of the authors of papers that caught my attention and invite them to present their work at the Abu Dhabi Machine Learning Meetups (or the Hong Kong ones for HK-based researchers). These sessions are a great way to learn directly from the researchers and get a better understanding of their work in a more pedagogical setting.
- Try out a couple of GitHub repos associated with papers I bookmarked. If anything interesting comes out of playing with the implementations—whether insights or practical tweaks—I’ll blog about it. Not necessarily aiming for something groundbreaking, but more as a way to deepen my understanding.
- Work through the stack of papers I’ve bookmarked from the conference. I’m particularly interested in topics like multimodal LLMs, Diffusion Transformers, and the Mamba architecture—these seem like promising directions worth exploring further.
- Start keeping tabs on the emerging themes and discussions as they develop toward ICML 2025. It’s always better to go into a conference with a clear idea of what to prioritize.
- Spend a bit more time understanding areas I’m less familiar with, like video-language models or the integration of text, audio, and video. These seem like foundational challenges, and it’s probably the next big frontier in AI.
Plenty to keep busy with. These conferences always leave me with a mix of curiosity and a bit of FOMO—there’s so much happening that you can’t possibly cover it all…
For those in Abu Dhabi (or Hong Kong), consider joining one of our upcoming Machine Learning Meetups. We’ll be discussing some of these trends in more depth, and it’s a great chance to learn from each other.
Wrapping up
NeurIPS 2024 brought a wide range of progress in AI/ML, from foundational work on multimodal models to practical applications in agents and generative systems. As always, it’s impossible to cover everything, but the conference gave me a good sense of where the field is heading and plenty of ideas to dig into. It’ll be interesting to see how these trends develop over the next year.
Are there any under-the-radar papers or trends I missed? Let me know!