[ICML 2018] Day 2 - Representation Learning, Networks and Relational Learning
[ICML 2018] Day 2 - Representation Learning, Networks and Relational Learning
The main conference began today (yesterday was the Tutorials). It started by an invited talk from Prof. Dawn Song on ``AI and Security: Lessons, Challenges and Future Directions’’, followed by the best paper award presentation on Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples.
Takeaways from the keynote ``AI and Security: Lessons, Challenges and Future Directions’’:
- AI can be improved by computer security, and computer security by AI (for example, to detect malicious code, one can compute the code graph, use a graph embedding technique to transform this code graph to a representative vector, and finally compare this vector using a cosine similarity to determine if the original code is malicious or not)
- differential privacy
- some models (especially deep nets) can memorize part of the training set (artefact of the learning); one should not be able to get the training set back by querying the model (think of credit card numbers, or other sensitive information, for example)
- Synergy between AI, computer security, and blockchain (read more about her work there…); for example, designing a marketplace for data where user are retributed for giving away their personal data, yet via a smart contract there is a guarantee that their data will only be use to fit machine learning models and that they will be payed for it, all that in total security for their privacy thanks to differential privacy techniques. I know, this is a mega combo of buzzwords, yet given Prof. Song track records, probably some substance there.
- Actually, Prof. Song is CEO and founder of a company on these ideas: Oasis Labs.



Takeaways from the best paper Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples:
- An adversarial example is a misclassified sample very similar (even identical to the human eye in the case of an image; think of a change of a few pixels) to a sample correctly classified with high confidence.
- This is annoying for the machine learner concerned about the robustness of his models, and this also presents a security threat: You can potentially fool an autonomous vehicle by modifying appropriately the road traffic signs.
- Such adversarial examples are relatively easy to generate.
- Researchers focus on defending their models against such models by obfuscating their gradients.
- This paper shows that this is a rather weak defense and breaks recent state-of-the-art methods.
- The speaker advocates for more evaluation (re-evaluation) appers: Over the 200 papers proposing a defense scheme, only 30 have been re-evaluated.
- Schneier’s Law: Anyone, from the most clueless amateur to the best cryptographer, can create an algorithm that he himself can’t break.
- Learn to attack, before trying to propose a defense scheme.
After this plenary session, the day was subdivided into three sessions (+ the evening poster session) with highly parallelized thematic tracks.
I attended the following sessions:
- Representation Learning (session 1)
- Unfortunately, Transfer and Multi-Task Learning was full. Working most of the time with non-labeled data I am interested in unsupervised, weakly and semi-supervised techniques. Embeddings it a hot topic currently, and gives promising results despite it is not always clear how an embedding contributes to the downstream tasks (if it was not extracted from it).
- Gaussian Processes + the last paper of Sparsity and Compressed Sensing (session 2A)
- Working with stochastic time series in continuous time, Gaussian Processes is a non-parametric bayesian technique which is compelling for that purpose. I have some experience fitting them using GPy, and used them as an alternative approach when modelling autoregressive asynchronous multivariate time series.
- Ranking and Preference Learning (session 2B)
- I went essentially to this session because one approach of quant trading can be viewed as learning to rank stocks according to some metric, and eventually merging lists of ranks and preferences.
- Networks and Relational Learning (session 3)
- I have worked extensively on this topic in the past, albeit not with deep learning techniques but rather with goold old stat-physics methods and old-fashioned hierarchical clustering (cf. review paper). This was the most inspiring session for me.
I focused on these specific papers:
- Online Convolutional Sparse Coding with Sample-Dependent Dictionary
- From fellow HKers. They propose a technique to save only a small basis of filters (for biomedical image compression / denoising / reconstruction), but then they are able to extend it massively (the bigger the basis, the more accurate for the representation) by using a linear transformation which is a learnt sample-dependent matrix of weights.
- Canonical Tensor Decomposition for Knowledge Base Completion
- From a former schoolmate now at Facebook AI Research. Super clear presentation. Code available on GitHub.

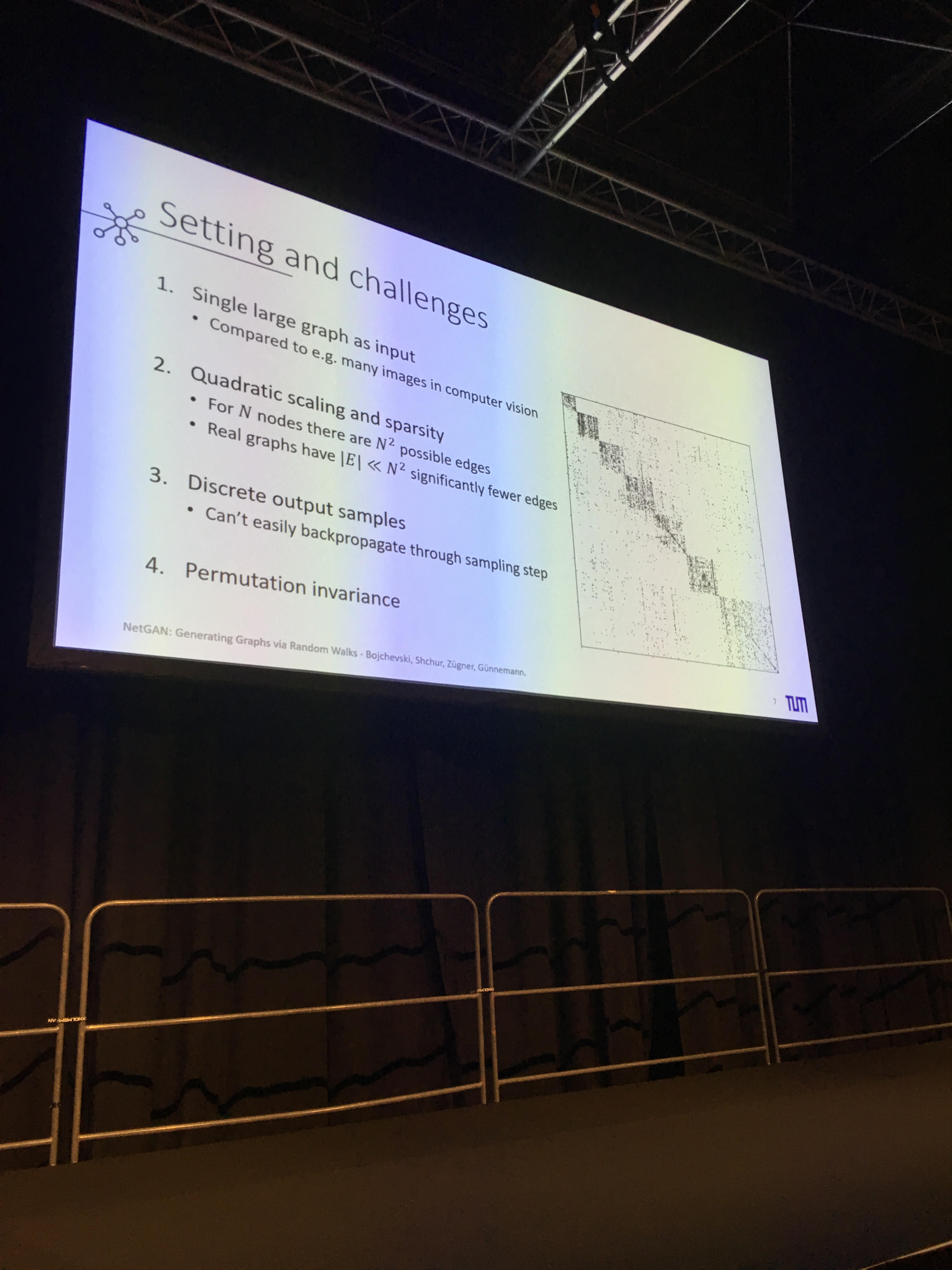
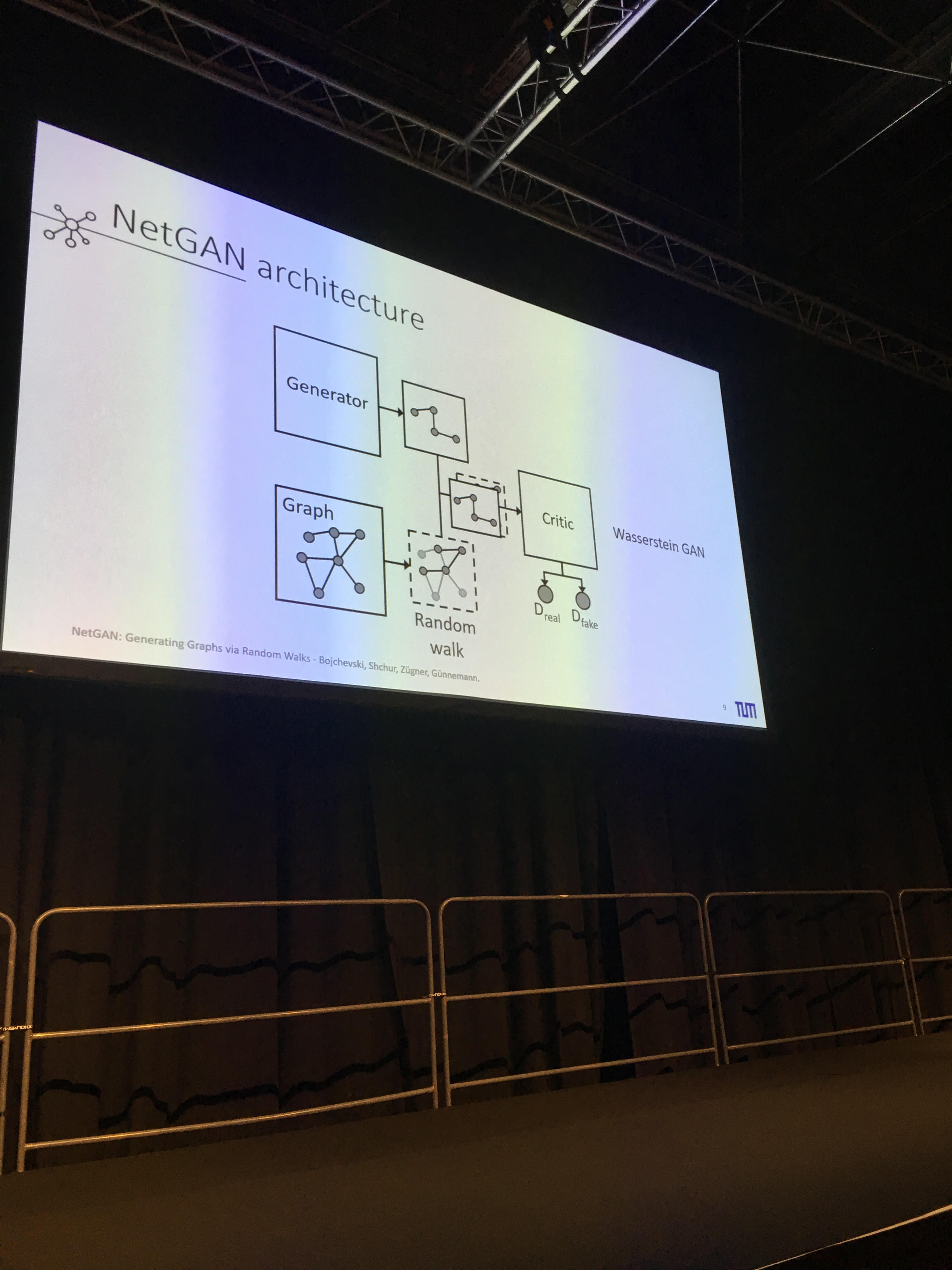
- NetGAN: Generating Graphs via Random Walks
- Super clear presentation. A GAN that can generate realistic graphs from a given graph in input. Can be tweaked to several graph having the same nodes. Gave me some interesting research ideas on financial correlations, their stylized facts, and the latent embedding space. More on that later. The speaker presented me its poster: Very didactic presentation. Code available on GitHub.


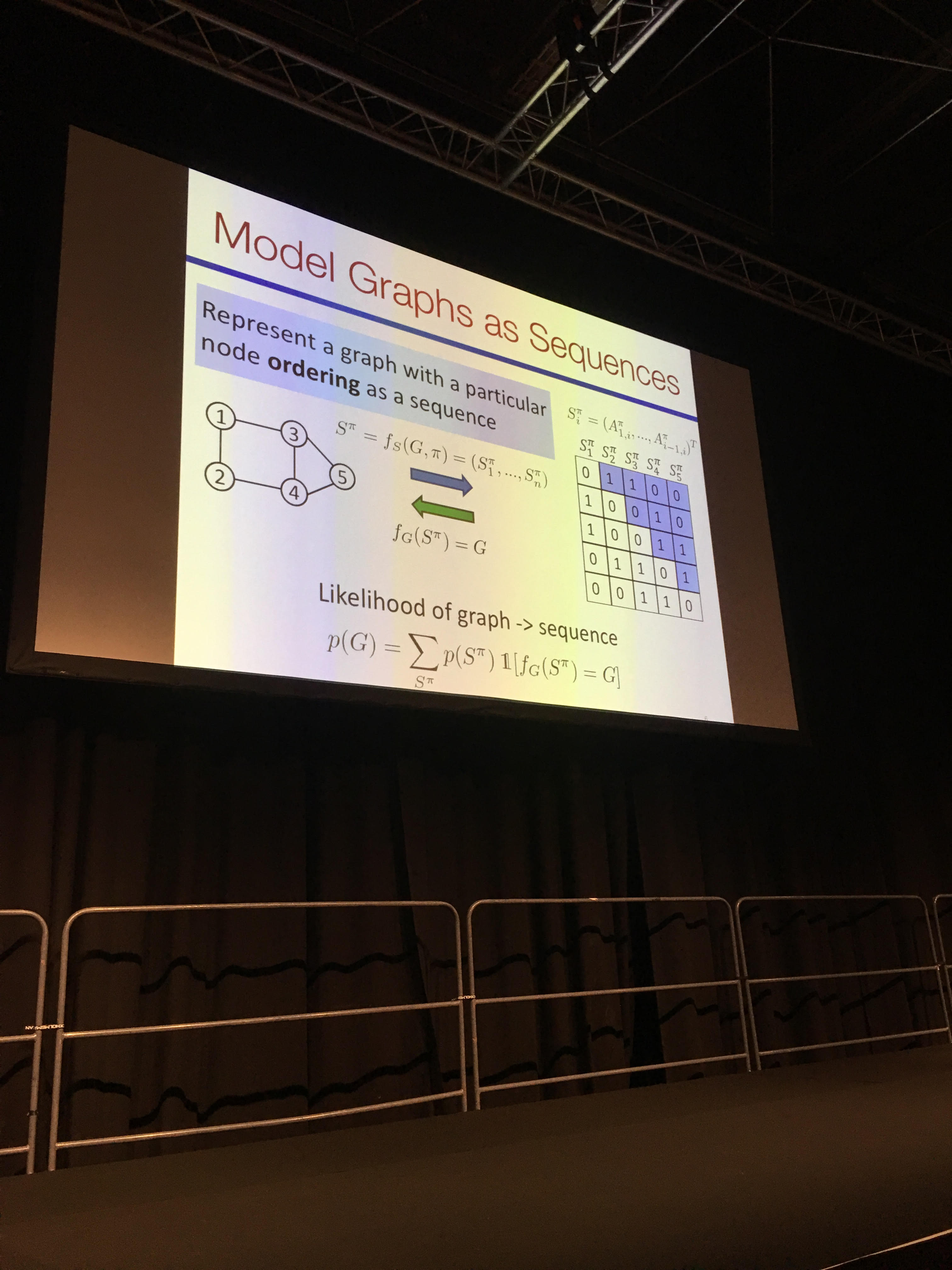
- GraphRNN: Generating Realistic Graphs with Deep Auto-regressive Models
- Generative model of graph using a sequence representation of the graph, and then applying RNN models. Code available on GitHub.
- CoVeR: Learning Covariate-Specific Vector Representations with Tensor Decompositions Conditioning the word embedding on the corpus on which the embedding was learned.
Program for tomorrow:
- Generative Models (session 1)
- Ranking and Preference Learning (session 2A)
- Supervised Learning (curriculum learning) or Deep Learning (Neural Network Architectures – for music and sequences) (session 2B)
- Natural Language and Speech Processing (first half) and Deep Learning (Neural Network Architectures – since there is our paper) (session 3)